I have created a stacked graph and now want the highest result to be outputted into text. Currently I have gotten it to output from the selectInput and the radioButtons to out put "Female from US are more susceptible to " and now I want it to be able to read out the highest stack from the graph to add to the end of that sentence but not sure how to do it.
width= 4,
wellPanel(width = 6, solidHeader = TRUE,
textOutput("selected_var")
)
),
box(width = 8, solidHeader = TRUE, status = "primary",
mainPanel(
plotlyOutput("coolplot", width = '900px', height = '600px')
)
)
Server
output$selected_var <- renderText({
paste(input$genderInput, " from ", input$Nationality, " are more susceptible to ")
})
output$coolplot <- renderPlotly({
ngo <-
ngo %>%
filter(Victim.Nationality == input$Nationality,
Victim.Gender == input$genderInput
)
p = ggplot(ngo, aes(x = Victim.Age, fill = Trafficking.Type)) +
geom_bar(position = "stack")
ggplotly(p) %>%
layout(showlegend = FALSE)
})
Hi,
In order for us to help you with your question, please provide us a minimal reprocudible example where you provide a minimal (dummy) dataset and code that can recreate the issue. One we have that, we can go from there. For help on creating a Reprex, see this guide:
A minimal reproducible example consists of the following items:
A minimal dataset, necessary to reproduce the issue
The minimal runnable code necessary to reproduce the issue, which can be run
on the given dataset, and including the necessary information on the used packages.
Let's quickly go over each one of these with examples:
Good luck!
Here is a sample of the data.
Victim Nationality
Victim Age
Trafficking Type
US
22
Child Labour
US
28
Child Labour
US
26
Domestic Servitude
United Kingdom
18
Child Labour
Spain
30
Labour Exploitation
US
33
Domestic Servitude
Spain
19
Labour Exploitation
United Kingdom
20
Domestic Servitude
Czech Republic
34
Labour Exploitation
Czech Republic
27
Domestic Servitude
Czech Republic
34
Domestic Servitude
US
22
Child Labour
United Kingdom
18
Child Labour
In this case the text would read out people from US who are 22 are more susceptible to Child Labour etc.
UI
dashboardBody(
column(
wellPanel(width = 6, solidHeader = TRUE, status = "primary",
selectInput("Nationality", "Choose victim nationality: ", choices = " "),
radioButtons("genderInput", "Choose Gender: ",
list("Female", "Male", "Other", "Unknown")
)
),
width= 4,
wellPanel(width = 6, solidHeader = TRUE,
textOutput("selected_var")
)
),
box(width = 8, solidHeader = TRUE, status = "primary",
mainPanel(
plotlyOutput("coolplot", width = '900px', height = '600px')
)
)
)
Server
traffickerNationalities = sort(unique(ngo$Trafficker.Nationality))
updateSelectInput(session, "TraffickerNation", choices = traffickerNationalities)
nationalities = sort(unique(ngo$Victim.Nationality))
updateSelectInput(session, "Nationality", choices = nationalities)
output$selected_var <- renderText({
paste(input$genderInput, " from ", input$Nationality, " are more susceptible to ")
})
output$coolplot <- renderPlotly({
ngo <-
ngo %>%
filter(Victim.Nationality == input$Nationality,
Victim.Gender == input$genderInput
)
p = ggplot(ngo, aes(x = Victim.Age, fill = Trafficking.Type)) +
geom_bar(position = "stack")
ggplotly(p) %>%
layout(showlegend = FALSE)
})
It's not entirely clear to me what you're trying to do, but it seems like you want to get at the 'trained' ggplot2 data that gets fed into plotly, which you can do this way:
library(plotly)
library(dplyr)
p <- ggplot(mtcars, aes(x = factor(cyl), fill = factor(vs))) +
geom_bar(position = "stack")
gg <- ggplotly(p, originalData = FALSE) %>%
layout(showlegend = FALSE)
plotly_data(gg) %>%
slice(which.max(y))
For more examples and explanation of what's happening here see https://plotly-r.com/improving-ggplotly.html#leveraging-statistical-output
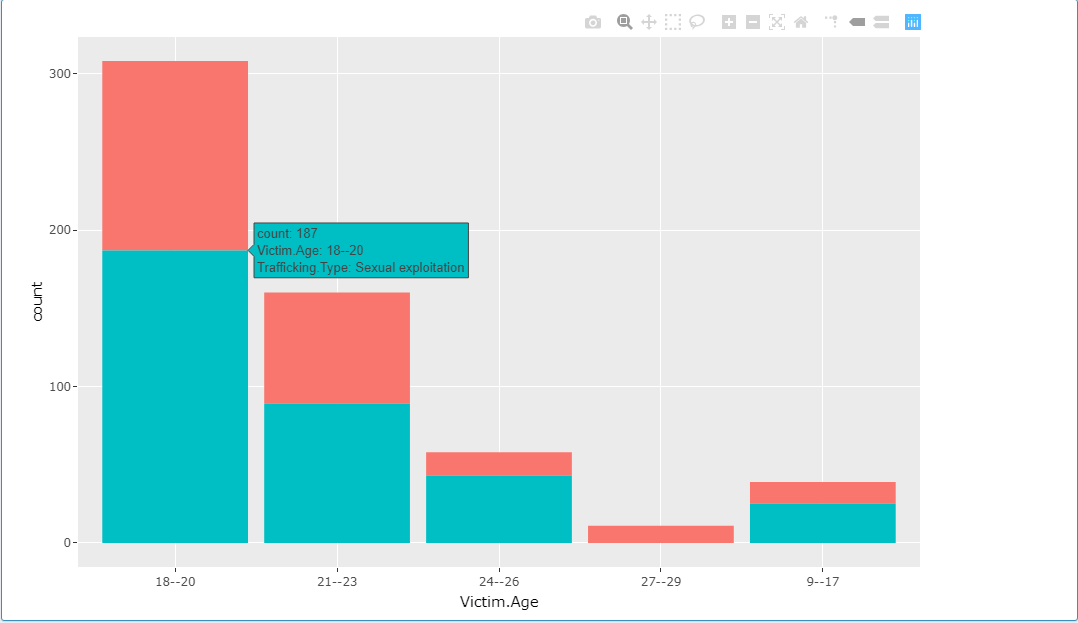
I'm not sure I explained myself very well, I have attached a photo of a part of the graph and in this case it should say females from RO are more susceptible to sexual exploitation between the ages of 18 - 20 and ignore the red above as is less than the 187 for the blue column. Essentially I am trying to link the largest part of the single column to text.
system
October 15, 2019, 5:38pm
6
This topic was automatically closed 54 days after the last reply. New replies are no longer allowed.