Hello.
I am currently studying the impact of resampled data on the predictive performance of a model.
For example, I learned that there are ways to increase the pattern of data by bootstrapping samples to get a distribution of performance, and there are ways to repeatedly run v-fold to get multiple performance values.
I recently found a package of tidyposterior.
It had a function to get the posterior distribution for multiple models.
How can I simply get the posterior distribution by Bayesian method for a single model?
I would like to get the posterior distribution from 10 results obtained from 10-fold.
Is there a package or function that you recommend?
You cannot. Those 10 models developed during 10-fold CV are used to generated the data that go into the Bayesian model. Your 10-fold models are random realizations of the population model. They provide replicates of the performance metric that are used in the model fit.
As an analogy, suppose you had 10 data points and wanted to do a t-test to see if their population mean was different than zero. You could not get a p-value for each sample; only for the collection of data.
After I asked the question, I came up with my own code to make it happen.
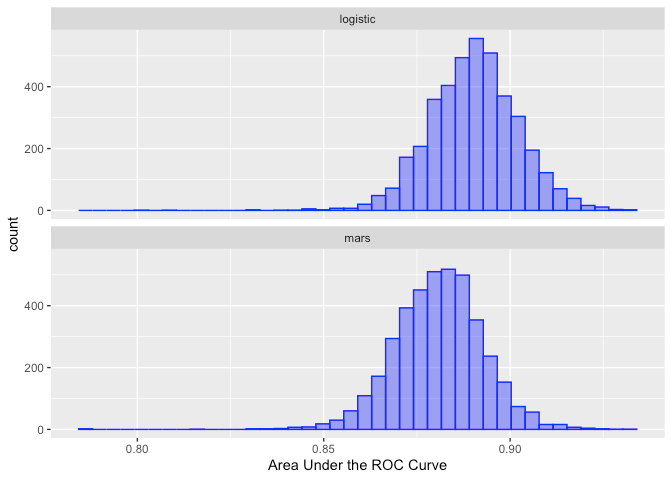
The following code was created to get the posterior distribution of performance for logistic.
The goal was to get the posterior distribution of the logistic of perf_mod.
The upper part of the figure below.
library(rstan)
resample_df <- structure(list(id = c("Fold01", "Fold02", "Fold03", "Fold04",
"Fold05", "Fold06", "Fold07", "Fold08", "Fold09", "Fold10"),
logistic = c(0.855873015873016, 0.933116883116883, 0.933793103448276,
0.86436170212766, 0.847402597402597, 0.911424903722721, 0.867137355584082,
0.88563829787234, 0.897946084724005, 0.906330749354005),
mars = c(0.845079365079365, 0.951298701298701, 0.937241379310345,
0.858377659574468, 0.853896103896104, 0.839537869062901,
0.858472400513479, 0.875664893617021, 0.897946084724005,
0.893733850129199)), row.names = c(NA, -10L), class = c("tbl_df",
"tbl", "data.frame"))
stan_code <- "
data {
int length;
real x[length];
}
parameters {
real mu;
real<lower=0> sigma;
}
model {
x ~ normal(mu, sigma);
}
"
data <- list(x = resample_df$logistic,
length = nrow(resample_df))
mod = rstan::stan_model(model_code = stan_code)
fit = rstan::sampling(mod,
data = data,
iter = 10000,
chains = 3)
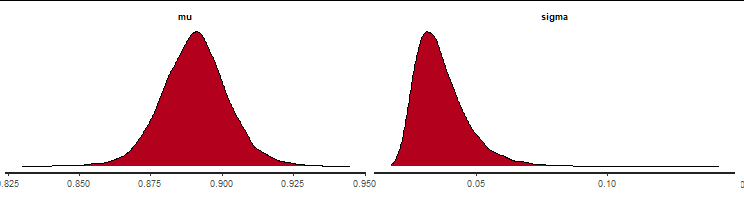
stan_dens(fit)
Doesn't this mean that the posterior distribution of the model's performance was obtained from 10 data points?
tidyposterior, with multiple models as inputs, automatically uses partial pooling. With two models, it is estimating 3 (or 4 if hetero_var = TRUE) parameters from 20 data points.