Hello!
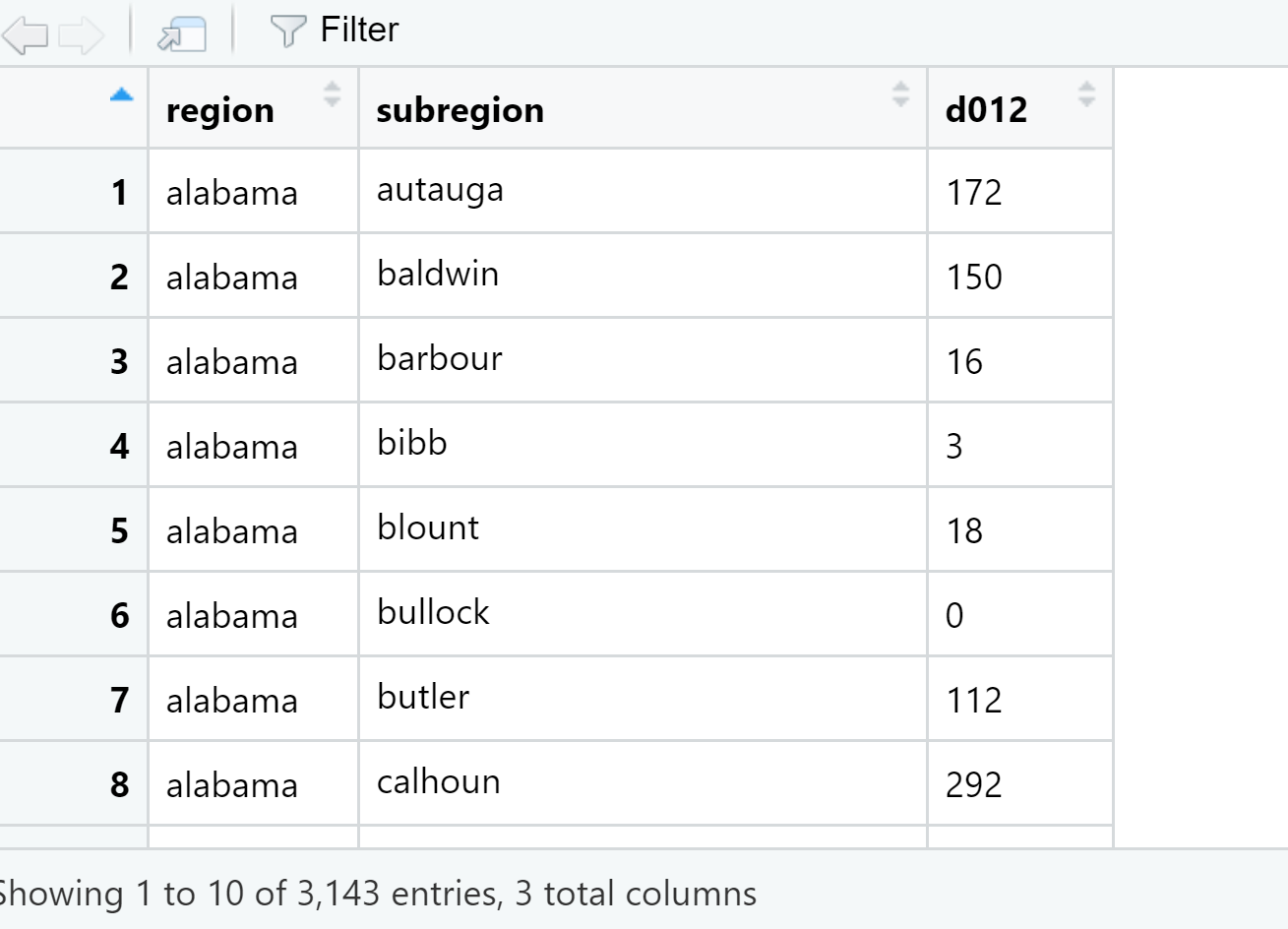
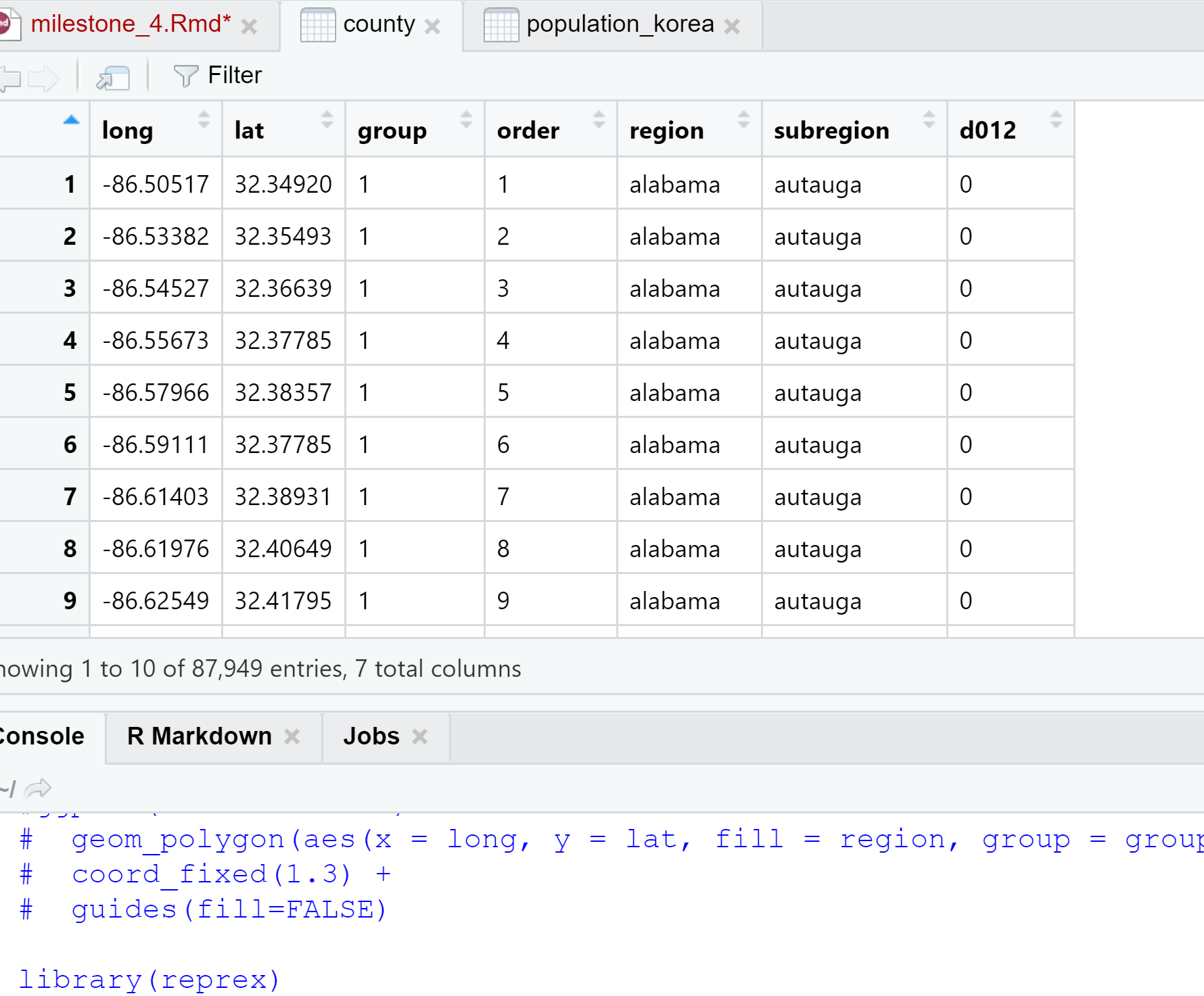
I have a project that I am working on (for my Gov 1005 Data Science class) where I am trying to map the population density of Korean individuals in various counties of the U.S. I have the county lat long data from map_data(county), and I have the population data by county/state in two separate files. But the county lat long data I have has several occurrences of counties and states because it needs to put every single coordinate on the map to make the outline of the shape.
My population data on the other hand only has one instance per county.
I've tried using all the various joins in r, but I can't seem to make it correctly join together the way I need it to! Right now, it only joins together baltimore county in Maryland and a random county in Nevada. How do I fix this?
Thank you so much!
My code is below:
#Want to change maps to show by county how many koreans live in each county
population_korea<- read_csv("data/Copy of DEC_10_SF1_PCT7_with_ann.csv") %>%
clean_names()
#> Error in read_csv("data/Copy of DEC_10_SF1_PCT7_with_ann.csv") %>% clean_names(): could not find function "%>%"
#HAS EVERTHING>> including alaska and hawaii
population_korea<- population_korea%>%
dplyr::select(geo_display_label,d012)
#> Error in population_korea %>% dplyr::select(geo_display_label, d012): could not find function "%>%"
population_korea<- population_korea %>%
separate(geo_display_label, into = c("subregion", "region"), sep = ", ") %>%
#split the geography column into county and state
na.exclude() %>%
filter(region != c("alaska", "hawaii"))#county doesn't have the shape files
#> Error in population_korea %>% separate(geo_display_label, into = c("subregion", : could not find function "%>%"
population_korea <- population_korea[c(2,1,3)]
#> Error in eval(expr, envir, enclos): object 'population_korea' not found
population_korea$subregion <- iconv((population_korea$subregion), to='ASCII//TRANSLIT')
#> Error in iconv((population_korea$subregion), to = "ASCII//TRANSLIT"): object 'population_korea' not found
#Take out all the accents
population_korea$region <- tolower(population_korea$region)#change to all lowercase
#> Error in tolower(population_korea$region): object 'population_korea' not found
population_korea$subregion <- tolower(population_korea$subregion)#change to all lowercase
#> Error in tolower(population_korea$subregion): object 'population_korea' not found
stopwords = c("county")
x = population_korea$subregion #Company column data
#> Error in eval(expr, envir, enclos): object 'population_korea' not found
x = removeWords(x,stopwords) #Remove stopwords
#> Error in removeWords(x, stopwords): could not find function "removeWords"
population_korea$subregion <- x
#> Error in eval(expr, envir, enclos): object 'x' not found
county<- map_data("county") %>%
mutate(d012 = "0") %>%
group_by(subregion) %>%
merge(population_korea, c("region","subregion"))
#> Error in map_data("county") %>% mutate(d012 = "0") %>% group_by(subregion) %>% : could not find function "%>%"
Created on 2019-10-30 by the reprex package (v0.3.0)