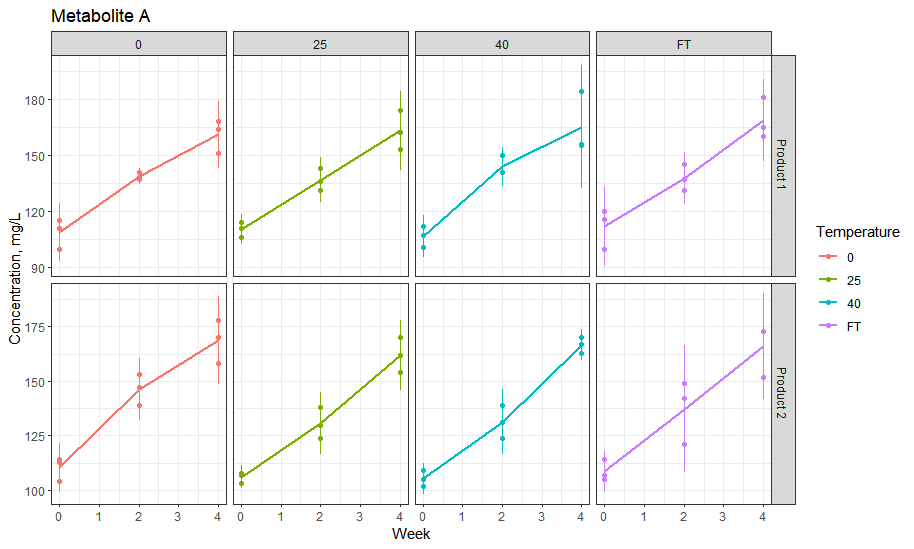
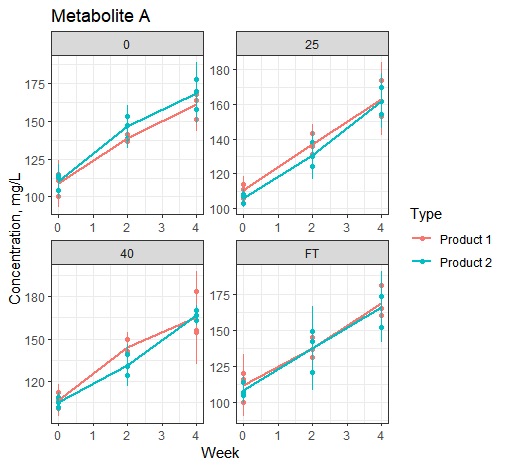
Hello everyone! I have a dataset with Metabolite concentration (triplicate measurement) with 2 Types (Product1, 2), in Time series (0,2,4 weeks) and in different Temperatures (0,25,40,FT). I'd like to plot mean and SD for each Product at each Timepoint and each Temperature with stat_summary.
However, stat_summary cannot identify colour as a variable - and pools all points from Type, hereby calculating/plotting the average and SD of all Products pooled. What I'd like to do is rather make mean+SD for each individual Product in different temperatures per Timepoint in dedicated colors.
How could it be done? Thank you ![]()
summary(dataLPstability)
dataLPstability$Type <- factor(dataLPstability$Type, levels = c('Product1,'Product2'), ordered = TRUE) #converting Formulation to factorial
dataLPstability$Temperature <- factor(dataLPstability$Temperature, levels = c('0','25','40','FT'), ordered = TRUE)
##Plotting
line.MetaboliteA <- ggplot(dataLPstability, mapping = aes(x=Time,y=MetaboliteA,color=Temperature, group=Type))+geom_point() + stat_summary(fun = "mean", geom= "line",size=1) + facet_grid(vars(Type),vars(Temperature), scales = "free")+ labs(x="Week", y="Concentration, mg/L", title="Metabolite A")
line.MetaboliteA + scale_x_continuous(breaks = scales::pretty_breaks(n = 6)) + theme_base()+ stat_summary(fun.data = "mean_sdl", fun.args=list(mult=2), geom= "linerange",color="blue",size=0.5)