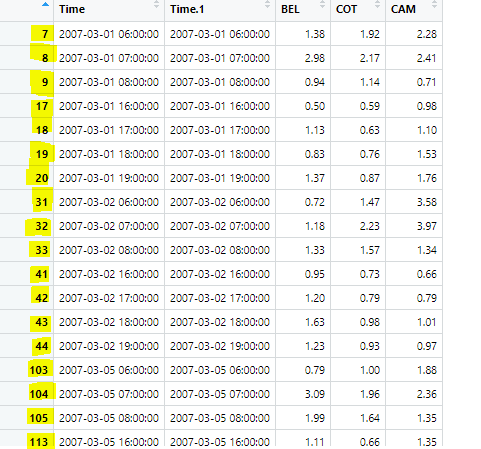
I am working on spatial and temporal classification in my data set. Due to this classification, I have a mix of the rows from the original dataset (as you see in the picture the row starts with the 7th, 8th, etc), but when I do a normalized transformation for each block, the row numbering starts in 1, 2, 3, 4, 5, etc. I would like to keep the row numbering from the first classification, not the normal numbering.
I may be wrong, but the numbers 7, 8, etc. are probably behaving more like a row name than a row number. What I mean by that is I expect the following to happen, if if I'm not terribly wrong.
df[7,] is going to extract the row with number 20
df["7",] will extract the first row
If that is indeed the case for you, I'll suggest to convert these to a column of row names, and let the row numbers being usual, i.e. start from 1. In that way, you'll continue to have the information you need.
If this is not an acceptable solution for you, you need to provide a reprex and share some more context as required. At the least, the reprex will need a copy-paste friendly data, and the code for "normalized transformation".