There is a data frame need to fix the consistency of the two columns.
I used this code to get the uniques values of three columns (pop1_number, pop2_number, pop3_number):
y <- x %>%
group_by(PROVINCE, DISTRICT, SUB_DISTRI, VILLAGE) %>%
summarise(number_1 = unique(pop1_NUMBER),
number_2 = unique(pop2_NUMBER),
number_3 = unique(pop3_number))
I got this error
Error: Problem with `summarise()` input `number_2`.
x Input `number_2` must be size 38 or 1, not 39.
i An earlier column had size 38.
i Input `number_2` is `unique(pop3_NUMBER)`.
i The error occurred in group 5333: PROVINCE = 11, DISTRICT = 15, SUB_DISTRI = 10, VILLAGE = 37
Then got each of these three columns unique values by this code:
The uniqueness of them was different. For pop1_number was 106444, for pop2_number was 106474, and for pop3_number was 106456.
I need to be the uniqueness of pop2_number and pop3_number 106444 too. This is what I am looking to fix.
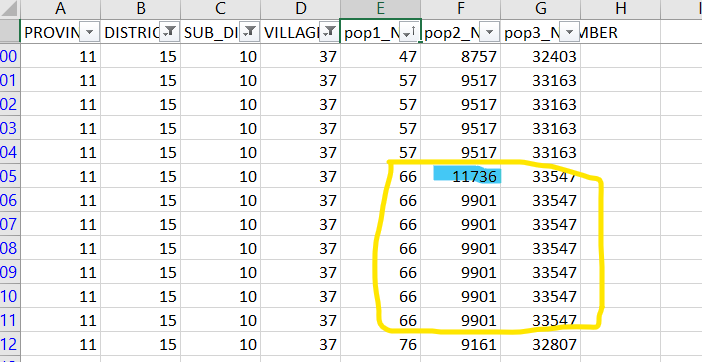
Then I checked those rows of the data frame, some of the row values swapped. As you see on the screenshot, row 137 values must be in row 138 and row 138 must be in 137. I stuck here on how to fix it.
I think you are misinterpreting the unique() function here.
When you use it, it will look for all unique values in a list and return them, but in different lists (or columns in a data frame) the number of unique values can vary. This is why the summary function fails. When you summarise, all outputs in the summarise variables need to be of the same length (usually 1). In your case, the first column number_1 has 38 unique values, and number_2 has 39, thus breaking the function.
I don't know exactly what the goal of the summary is you are trying to accomplish, can you describe a bit more what the output data frame should look like?
Thank @pieterjanvc, you are right about the number of unique for each of them. As I wrote pop1_number has 106444 unique numbers, while pop2_number has 106470 and pop3_number has 106456 unique numbers. But what I want is that some rows in the data frame have swapped, if fix them then the number of unique for each of them will be 106444. I do not know how to do.
If you filter the error you will figure out the problem. they must be consistent, but here has a problem.
Swapping rows is not going to change the uniqueness, as this is based on a column which will stay the same. I think what you maybe meant is swapping values within a row so they are in a different column
You think the 'error' stems from "PROVINCE = 11, DISTRICT = 15, SUB_DISTRI = 10, VILLAGE = 37", but when I run it, I get "PROVINCE = 11, DISTRICT = 5, SUB_DISTRI = 150, VILLAGE = 12". There are probably many places where this uniqueness number per column might not work.
Looking at your data in more detail, are you actually trying to get rid of duplicate values? Because when I look at your data, a lot of rows are duplicated. You can easily fix this like so:
myData = myData %>% distinct()
This reduces the number of rows from 447195 to 106528
If you now like to see how many unique values there are in the last 3 columns and see where it goes wrong by group do this:
#Count the number of unique values per group
myData = myData %>% distinct() %>%
group_by(PROVINCE, DISTRICT, SUB_DISTRI, VILLAGE) %>%
summarise(number_1_uniqueN = length(unique(pop1_NUMBER)),
number_2_uniqueN = length(unique(pop2_NUMBER)),
number_3_uniqueN = length(unique(pop3_NUMBER)),
.groups = "drop")
#Check where number_1-3 are not identical
notCorrect = myData %>% rowwise() %>%
mutate(
sameUniqueN = all(
number_1_uniqueN ==
c(number_2_uniqueN, number_3_uniqueN)
)) %>%
filter(!sameUniqueN)
I get a list of 33 groups where things go wrong...
I still don't see the use of this whole exercise, so please describe better what it is you want to understand from all this anaysis.
As you see the highlighted cell number doesn't match with its following cells of column F. In pop1_number is 66, pop2 must be 9901 and pop3 is 33547. This a sample, there are 26 problems for pop2_number and 10 for pop3_number.
It has swapped with this one:
Note: I can do it manually in this data frame. But there is another data frame that has more 2k problem same as this.
Thank you
It's still all very confusing ... There are also scenarios in your data where there are 2 different pop2 and pop3 values for the same pop1 or even more. What to do in those cases???
Here is some code that will filter out all those instances and you can have a look at what I mean
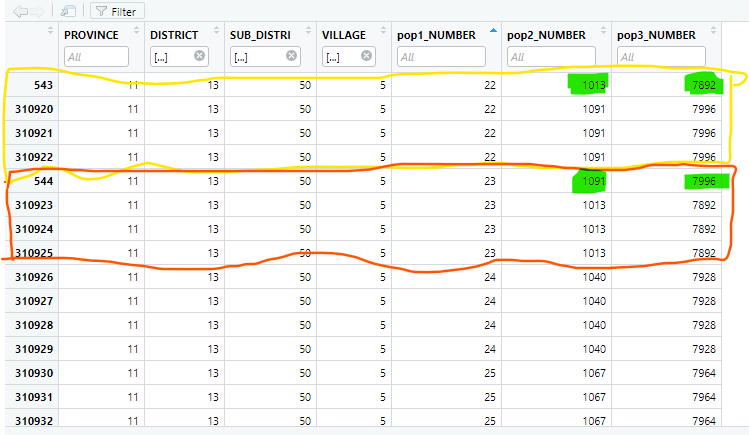
As you see I want to swap 1013 with1091 in pop2_NUBER and 7892 with 7996 in pop3_NUMBER. By fixing them they will get consistent.
On the right side, their row number are 543 and 544 in the data frame.