Hi,
I want to turn scientific notation in regression p-value output in tibble off.
Options(scipen=999) does not work.
How to do it ?
Thanks.
Thankyou @nirgrahamuk, it works but looks ugly.
mutate_if(is.numeric, round, 5)

Is it possible to have cells filled up to eg. 4 decimal places everywhere ?
Hi, @siddharthprabhu your SO solution doesn't work:
library(tidyverse)
fun <- function(slice, keys) {
broom::tidy(lm(Petal.Length ~ Sepal.Length, data = slice))
}
x <- iris %>%
group_by(Species) %>%
group_modify(fun)
options(pillar.sigfig = 4)
tb <- tibble(x=x)
tb
Still in p.value column there is a scientific notation visible.
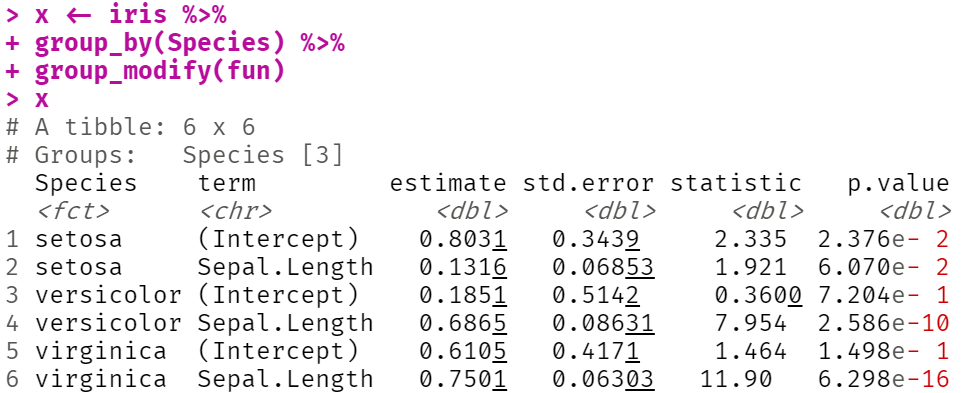
scientific notation, with 4 significant digits...
1 Like
@Andrzej I answered your second question. nirgrahamuk's post addresses your first.
Hi,
I would like an output in tibble like this below if possible, please:

If you want to get into the guts of it, you can , but formatting numbers consistently is a trickier puzzle than you might think. here is an adhoc example where I show we can do arbitrary things to how tibbles print
library(tidyverse)
fun <- function(slice, keys) {
broom::tidy(lm(Petal.Length ~ Sepal.Length, data = slice))
}
x <- iris %>%
group_by(Species) %>%
group_modify(fun)
options(pillar.sigfig = 4)
tb <- as_tibble(x)
library(pillar)
format.pillar_shaft_decimal <- function (x, width, ...)
{
if (length(x$dec$num) == 0L)
return(character())
if (width < pillar:::get_min_width(x)) {
stop("Need at least width ", pillar:::get_min_width(x),
", requested ", width, ".", call. = FALSE)
}
if (width >= pillar:::get_width(x$dec)) {
row <- pillar:::assemble_decimal(x$dec)
row <- stringr::str_replace_all(row," ","X") # why not turn spaces to X's
}
else {
row <- pillar:::assemble_decimal(x$sci)
}
used_width <- pillar:::get_max_extent(row)
row <- paste0(strrep(" ", width - used_width), row)
pillar:::new_ornament(row, width = width, align = "right")
}
assignInNamespace("format.pillar_shaft_decimal", format.pillar_shaft_decimal, ns="pillar")
#throws an error but seems to work anyway
tb %>% mutate_if(is.numeric,~round(.,digits=4))
# A tibble: 6 x 6
Species term estimate std.error statistic p.value
<fct> <chr> <dbl> <dbl> <dbl> <dbl>
1 setosa (Intercept) 0.8031 0.3439 2.335 0.0238
2 setosa Sepal.Length 0.1316 0.0685 1.921 0.0607
3 versicolor (Intercept) 0.1851 0.5142 0.36X 0.7204
4 versicolor Sepal.Length 0.6865 0.0863 7.954 0XXXXX
5 virginica (Intercept) 0.6105 0.4171 1.464 0.1498
6 virginica Sepal.Length 0.7501 0.063X 11.90X 0XXXXXThank you very much indeed,
it looks much more advanced than I think, but this is something new to learn today.
A lot of easier to keep it as data frame:
library(tidyverse)
fun <- function(slice, keys) {
broom::tidy(lm(Petal.Length ~ Sepal.Length, data = slice))
}
iris %>%
group_by(Species) %>%
group_modify(fun) %>% mutate_if(is.numeric, round, 4) %>% as.data.frame()
#> `mutate_if()` ignored the following grouping variables:
#> Column `Species`
#> Species term estimate std.error statistic p.value
#> 1 setosa (Intercept) 0.8031 0.3439 2.3353 0.0238
#> 2 setosa Sepal.Length 0.1316 0.0685 1.9209 0.0607
#> 3 versicolor (Intercept) 0.1851 0.5142 0.3600 0.7204
#> 4 versicolor Sepal.Length 0.6865 0.0863 7.9538 0.0000
#> 5 virginica (Intercept) 0.6105 0.4171 1.4636 0.1498
#> 6 virginica Sepal.Length 0.7501 0.0630 11.9011 0.0000
Created on 2020-05-01 by the reprex package (v0.3.0)
Example code based on this:
https://speakerdeck.com/romainfrancois/n-cool-number-dplyr-things?slide=4
This topic was automatically closed 7 days after the last reply. New replies are no longer allowed.