I have a dataset with 10 column, that are my features, and 1732 row that are my registrations. This registration are divided in 15 classes, so I have several registration for every class in my dataset. My goal is to define what is the most important feature, the one that brings more variance between classes.
I'm trying to use PCA, but because of the several registration for every classes it's difficult to find the right way of use oof this method.
I would standardize columns, train a glmnet model with family = "multinomial", and present the coefficients with largest magnitude.
PCA is an unsupervised method, so I don't think it can accomplish your objective. In other words, you have a "y variable", but PCA "only works on the x's."
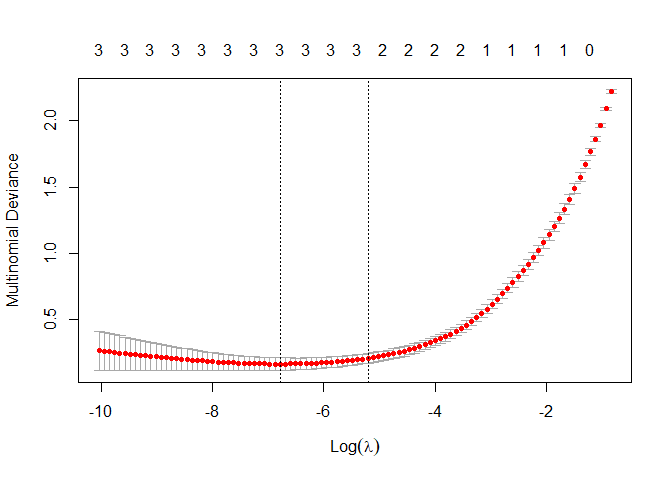
Yes. glmnet has two hyperparameters that control variable shrinkage. Of the two, lambda is the most important. A plot of cross-validated error vs lambda shows the result of the tuning, and ideally has a "U" shape for the succesful identification of lambda value that minimizes cross-validated error by balancing fitting and over-fitting.
ok thank you! but my goal is to define the features that bring more variance to the dataset.. for example in the iris dataset, which among sepal.length sepal.width, petal.length and petal.width creates more difference between the classes setosa, verisicolor and virginica
Yes, that what fitting the model and observing the standardized coefficients. For example, for classifying Species setosa, Petal.Length has the largest magnitude coefficient (-4.8), Sepal.Width weaker (1.01), Petal.Width close to zero, and Sepal.Length dropped entirely.
Interpretation is a little tricky when there is very significant multicollinearity.
in setosa petal.length is -4.8 and sepal.width is 1.01.. so I have to consider the absolute value? what is the difference between a negative and a positive value? Is like a correlation?
They're coefficients in logistic regressions. Increasing petal.length drastically decreases the probability of species setosa. Sorry that I can't answer all these questions in a few sentences. Regression, coefficients, Logistic regression, etc. are fundamental topics in statistics and all together would be taught over an entire semester.
Yes. Logistic regression is the statistical approach to predicting TRUE/FALSE values, predicting a category (PASS/FAIL, APPROVED/REJETED, ...), or multiple categories either ordered (ordinal) or unordered (nominal).
Regularized regression (glmnet, lasso, ridge regression) is a more contemporary way to make linear models when there are many predictor variables with possible multicollinearity, which was challenging / required very deliberate decisions traditionally.
Actually, there are many models you can use for your classification task. Glm models are one possibility. You can use tree-vased models as well. After that, take a look at vip package which gives methods to discover most important variables/features in your model. Read documentation to get feeling about how it works.
Thanks! This is very interesting. I find this code:
library(vip)
# Load the sample data
data(mtcars)
# Fit a projection pursuit regression model
model <- ppr(mpg ~ ., data = mtcars, nterms = 1)
# Construct variable importance plot
vip(model, method = "firm")
but I don't understand what is "importance" in the graph.. how is it calculate?
There are no simple answers.. Please see the package's vignette. You'll find all you need. Be aware of two main approaches, model specific and model agnostic ones. You got to a point where there are no shortcuts and you have to get familiar with all the nuances of those methods. Otherwise you won't be able to explain your model, understand its predictive capabilities and actual relationships among variables.