I am engaged in a college project in R which is all about the application of logistic regression.
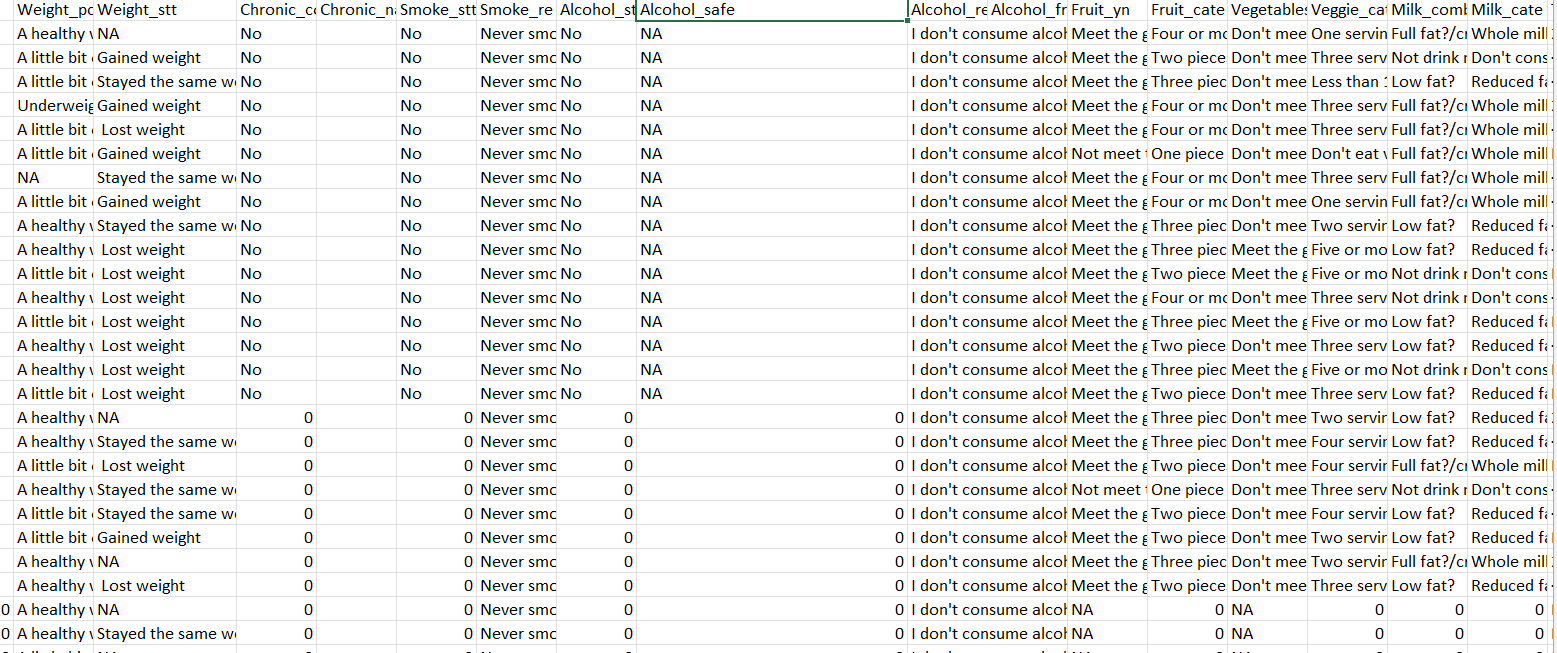
Whatever the data set was given to me , I found out that there are lot blank spaces present and so for this I converted all the blank spaces to NA and after applying glm I found out that the output is not showing correctly as there are missing values in the dataset.
I have applied na.omit() in R to delete the NA values but as I am doing this all columns and rows are getting deleted. I want only na to get deleted in the cells where na values are present.
If anyone can help me out regarding above facts it will be nice help for me to accomplish my project work and also if other information is required please let me know.
The missing values are present in the the dataset where character values are present and I want to replace the missing values such that there will be no errors when I do glm.
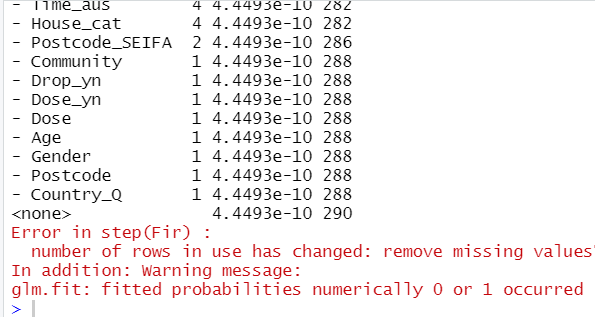
In the data set screenshot given above, it can be observed that NA values are present and when I am trying to use na.omit() all the contents of the rows and columns are getting deleted.
Regarding above facts, if anyone has any idea how to solve the issue it will be much helpful for me.
You can assign in your criteria, what value to replace these NA´s, in my case I use to asign 0 or 0.0 as the last code. (0.0 to recognize which values were NA´s)
If your ploblem are NA´s, sometimes we must use a critical thinking or criteria in these values, and sometimes you have to replace these for zero values.
I hope this helps, let´s change NA´s values with that code and try again
Hello everyone!
I would disagree with @bustosmiguel. Simply replacing missing values with 0 is commonly not what you want and can result in very wrong results. na.omitis the right call there. I suspect by your description that either there is a column with only NAs in your dataset or there is at least one NA in each row, so that na.omit() returns an empty data.frame. Since you are using the tidyverse anyway, you can filter() the rows that have NAs in the columns you want.
In your case this would be something like
AA22 %>%
filter(!is.na(Time3),
!is.na(Comunity),
... # repeat for all
)
You can make this less cumbersome by using if_any() and any_of()
However, if this also results an empty data frame, you dont have any complete cases. In this case it may be necessary to not consider certain parameters in your glm. Check which parameters have many missing cases by running:
In base R, you could also subset your dataset to only those columns that you want to include in the glm AA22[c("Time3", "Community", ...)] # add your columns, running na.omit() should then return the same as the dplyr-approach above (however missing the additional columns).
Hope this helps!