Hi, I want to format a Tabular report. so that it can show two summaries.
The report is required in below format:
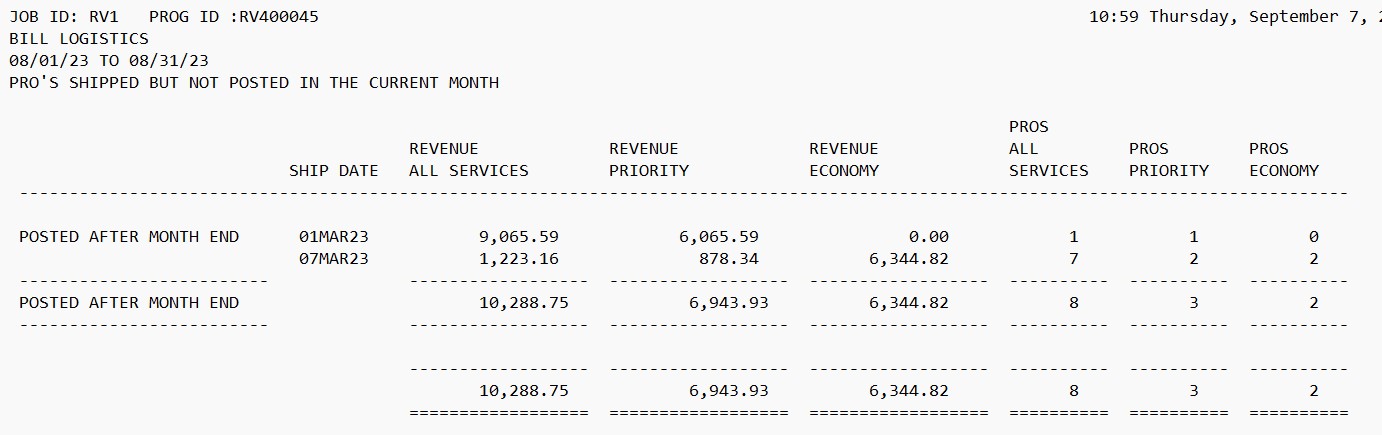
I used the below R code:
install.packages("flextable")
install.packages("janitor")
install.packages("officer")
install.packages("dplyr")
library("flextable")
library("officer")
library("magrittr")
library("janitor")
library("dplyr")
df<- read.csv("C:\Users\M68\Downloads\RV1.csv",sep='|',header=TRUE)
#Adding totals
df1<-df%>% adorn_totals("row")
#Keeping only required columns
df1<-subset(df1,select=c(X_type_,shpdt,revenue,revprty,revecon,c,tp,te))
#Renaming column names
colnames(df1) <- c('TYPE','SHIP DATE','REVENUE\n ALL SERVICES','REVENUE\n PRIORITY','REVENUE\n ECONOMY','PROS\n ALL\n SERVICES','PROS\n PRIORITY','PROS\n ECONOMY')
#Adding summary records again
df2<-subset(df1, TYPE=='-' | 'SHIP DATE' == '-')
df2 <- rbind(df1,df2)
#Creating a report
report<-flextable(df2) %>%
#width of columns
width(j=2:3, width=2) %>% width(j=1, width=2.5) %>%
#alignment of columns
align(j=2:3, align="center", part="all") %>%
align(j=1, align="left",part="all") %>%
add_header_lines(values = paste("JOB ID: RV1 :RV1
BILL LOGISTICS
08/01/23 TO 08/31/23
PRO'S SHIPPED BUT NOT POSTED IN THE CURRENT MONTH", strrep(" ", 30), sep = ""))
Im unable to get the desired format result. any help in this
