Hello everybody,
I have the following situation. I'am working on time series database and there are data about wastewater plant, days, and gene measure(df_1)
I would like to create a new column (city) based on other (plant). The particularity is that each plant is reflecting the behaviour of one, two, three or more cities (df_2). I have tried to create the column based on another (mutate(city=(case_when ...) but I don't know how to automatically replicate the rows so that plants that join one, two or three cities can be completed
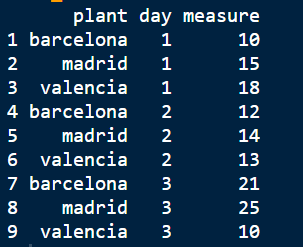
My data set initial:
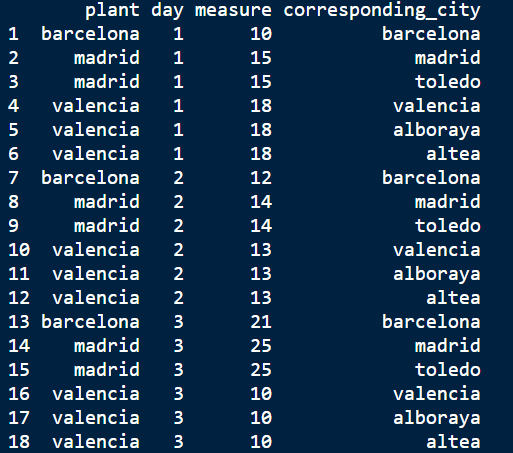
The dataset that I would like to create with the column "corresponding city":
I will try to simplify my initial and final database (df_1 and df_2) with the following example.
Thank yoy for your help
#barcelona with barcelona
#madrid with madrid, toledo
#valencia with valencia, alboraya, altea
df_1<-data.frame(plant= c("barcelona", "madrid", "valencia",
"barcelona", "madrid", "valencia",
"barcelona", "madrid", "valencia"),
day= c(1,1,1,
2,2,2,
3,3,3),
measure= c(10, 15, 18,
12, 14, 13,
21, 25, 10))
df_1
#Dataset that I want to create.
df_2<-data.frame(plant= c("barcelona", "madrid", "madrid", "valencia","valencia","valencia",
"barcelona", "madrid", "madrid", "valencia","valencia","valencia",
"barcelona", "madrid", "madrid", "valencia","valencia","valencia"),
day= c(1,1,1,1,1,1,
2,2,2,2,2,2,
3,3,3,3,3,3),
measure= c(10, 15, 15, 18, 18, 18,
12, 14, 14, 13, 13, 13,
21, 25, 25, 10, 10, 10),
corresponding_city= c("barcelona", "madrid", "toledo", "valencia", "alboraya","altea",
"barcelona", "madrid", "toledo", "valencia", "alboraya","altea",
"barcelona", "madrid", "toledo", "valencia", "alboraya","altea"))
df_2