Hi,
I have a matrix with 4 rows (different groups), and 10,000 columns. Each cell contains a p-value.
In addition, I have a vector named alpha, with 1000 values from 0 to 1.
I need to compare each alpha value, to the 10,000 p-values of the first matrix raw.
I need to count how many p-values are smaller than the alpha.
This is my code:
alpha<-seq(from=0,to=1,by=0.001)
for (i in 1:length(alpha)) {
treshold<-alpha[i]
for (j in 1:N) {
my.true<-p.values[1,j]<treshold
results<-matrix(my.true, nrow = 1000, ncol = N, byrow = TRUE)[i,j]
}
}
Mi idea was to get TRUE or FALSE for each value, and then count how many TRUEs I got for each alpha. Finally divide these values by 10,000 in order to get the percentage of the p-values smaller than alpha.
My code doesn't work. It seems like it runs for the first alpha and doesn't continue to the following one.
I suggest using the ecdf function to calculate the empirical cumulative distribution of each row.
set.seed(1)
bigm <- matrix (runif(40000), nrow = 4, ncol = 10000)
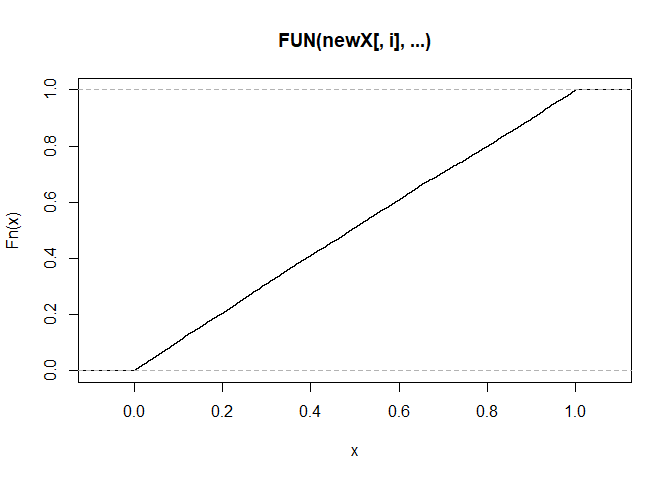
ECDFs <- apply(bigm, MARGIN = 1, ecdf) #get an ecdf for each row, saved in a list.
plot(ECDFs[[1]])
#what fraction of the values are <= 0.05 in row 1?
ECDFs[[1]](0.05)
#> [1] 0.0519
#Make a distribution peaked near 0.05
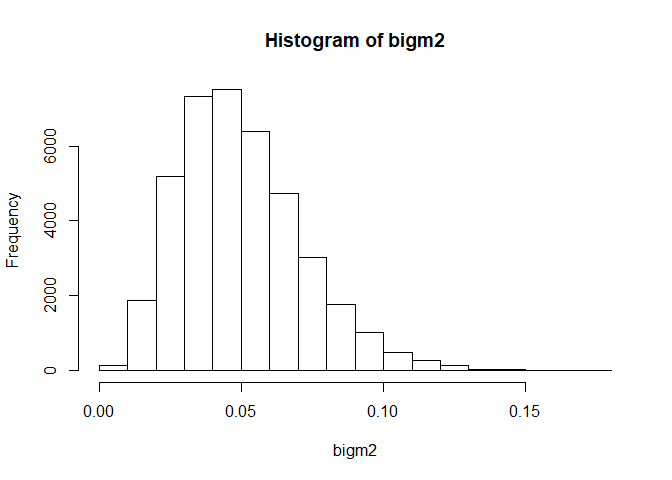
bigm2 <- matrix(rbeta(40000, shape1 = 5, shape2 = 95), nrow = 4)
hist(bigm2)
Thank you! If I got it right, following your suggested code I get the values of raw 1 which are smaller than 0.05. I was requested to find for each alpha (0:1, 1000 values) how many values from the first matrix raw are smaller than the alpha. That's where I get stuck, I'm new in R and I'm not sure how to write a code to run over the values of the first raw for each alpha value.
At the end, what I need to get is a fraction of how many values from the 10,000 (first raw) are smaller than the specific alpha X 1,000 (one fraction for each alpha).