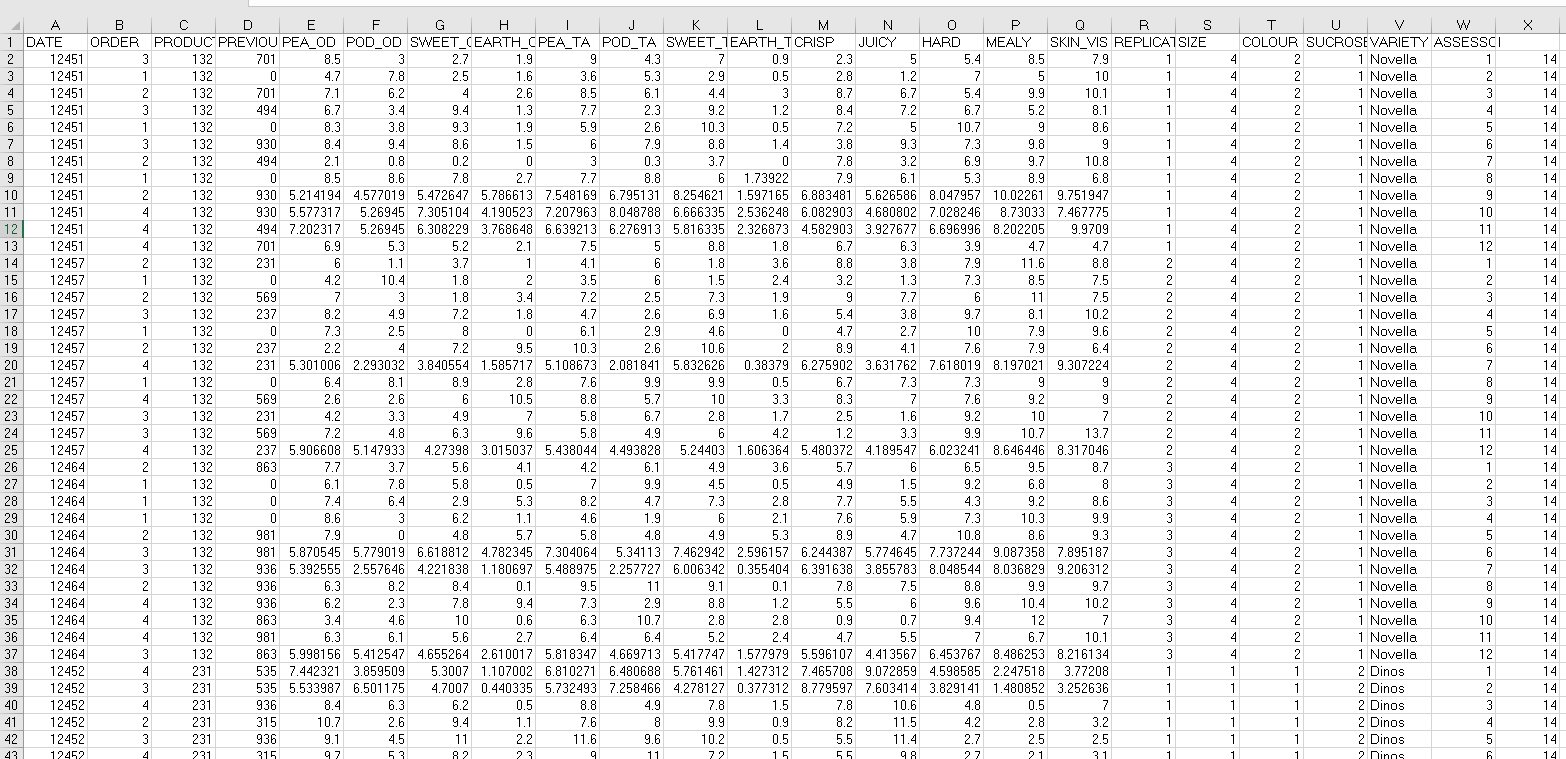
It works!! Thank you so very much for your help! The output is as follows:
structure(list(DATE = c(12451, 12451, 12451, 12451, 12451, 12451,
12451, 12451, 12451, 12451, 12451, 12451, 12457, 12457, 12457,
12457, 12457, 12457, 12457, 12457), ORDER = c(3, 1, 2, 3, 1,
3, 2, 1, 2, 4, 4, 4, 2, 1, 2, 3, 1, 2, 4, 1), PRODUCT = c(132,
132, 132, 132, 132, 132, 132, 132, 132, 132, 132, 132, 132, 132,
132, 132, 132, 132, 132, 132), PREVIOUS = c(701, 0, 701, 494,
0, 930, 494, 0, 930, 930, 494, 701, 231, 0, 569, 237, 0, 237,
231, 0), PEA_OD = c(8.5, 4.7, 7.1, 6.7, 8.3, 8.4, 2.1, 8.5, 5.21419360177377,
5.57731725951917, 7.20231725951917, 6.9, 6, 4.2, 7, 8.2, 7.3,
2.2, 5.30100604717383, 6.4), POD_OD = c(3, 7.8, 6.2, 3.4, 3.8,
9.4, 0.8, 8.6, 4.57701898460361, 5.26945040793965, 5.26945040793965,
5.3, 1.1, 10.4, 3, 4.9, 2.5, 4, 2.29303167439163, 8.1), SWEET_OD = c(2.7,
2.5, 4, 9.4, 9.3, 8.6, 0.2, 7.8, 5.47264729215009, 7.30510372614687,
6.30822872614687, 5.2, 3.7, 1.8, 1.8, 7.2, 8, 7.2, 3.84055354006671,
8.9), EARTH_OD = c(1.9, 1.6, 2.6, 1.3, 1.9, 1.5, 0, 2.7, 5.7866127989587,
4.19052270909193, 3.76864770909193, 2.1, 1, 2, 3.4, 1.8, 0, 9.5,
1.58571670252911, 2.8), PEA_TA = c(9, 3.6, 8.5, 7.7, 5.9, 6,
3, 7.7, 7.54816857744912, 7.20796304374728, 6.63921304374728,
7.5, 4.1, 3.5, 7.2, 4.7, 6.1, 10.3, 5.10867287368889, 7.6), POD_TA = c(4.3,
5.3, 6.1, 2.3, 2.6, 7.9, 0.3, 8.8, 6.79513093017187, 8.048787860617,
6.276912860617, 5, 6, 6, 2.5, 2.6, 2.9, 2.6, 2.08184102467404,
9.9), SWEET_TA = c(7, 2.9, 4.4, 9.2, 10.3, 8.8, 3.7, 6, 8.2546213168602,
6.66633455383992, 5.81633455383992, 8.8, 1.8, 1.5, 7.3, 6.9,
4.6, 10.6, 5.83262566182334, 9.9), EARTH_TA = c(0.9, 0.5, 3,
1.2, 0.5, 1.4, 0, 1.73922043934608, 1.59716541970052, 2.53624849458696,
2.32687349458696, 1.8, 3.6, 2.4, 1.9, 1.6, 0, 2, 0.383789890957604,
0.5), CRISP = c(2.3, 2.8, 8.7, 8.4, 7.2, 3.8, 7.8, 7.9, 6.88348124370722,
6.08290281524388, 4.58290281524388, 6.7, 8.8, 3.2, 9, 5.4, 4.7,
8.9, 6.27590214931074, 6.7), JUICY = c(5, 1.2, 6.7, 7.2, 5, 9.3,
3.2, 6.1, 5.6265857269369, 4.68080246765387, 3.92767746765387,
6.3, 3.8, 1.3, 7.7, 3.8, 2.7, 4.1, 3.63176231961318, 7.3), HARD = c(5.4,
7, 5.4, 6.7, 10.7, 7.3, 6.9, 5.3, 8.04795682485949, 7.02824617285958,
6.69699617285958, 3.9, 7.9, 7.3, 6, 9.7, 10, 7.6, 7.61801879523133,
7.3), MEALY = c(8.5, 5, 9.9, 5.2, 9, 9.8, 9.7, 8.9, 10.0226119740377,
8.73032980363849, 8.20220480363849, 4.7, 11.6, 8.5, 11, 8.1,
7.9, 7.9, 8.19702118688969, 9), SKIN_VIS = c(7.9, 10, 10.1, 8.1,
8.6, 9, 10.8, 6.8, 9.75194739618463, 7.46777524965843, 9.97090024965843,
4.7, 8.8, 7.5, 7.5, 10.2, 9.6, 6.4, 9.30722390092357, 9), REPLICAT = c(1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2), SIZE = c(4,
4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4), COLOUR = c(2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2), SUCROSE = c(1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1), VARIETY = c("Novella",
"Novella", "Novella", "Novella", "Novella", "Novella", "Novella",
"Novella", "Novella", "Novella", "Novella", "Novella", "Novella",
"Novella", "Novella", "Novella", "Novella", "Novella", "Novella",
"Novella"), ASSESSOR = c(1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12,
1, 2, 3, 4, 5, 6, 7, 8), I = c(14, 14, 14, 14, 14, 14, 14, 14,
14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14, 14)), row.names = c(NA,
-20L), class = c("tbl_df", "tbl", "data.frame"))
If I open the AvgProdAssess data frame it show the table with the averages