Hello,
the adoption of APIs built in R using the plumber package and deployed to RSC becomes more widespread in our organisation. It also means that our services become increasingly large and more complicated, especially when they interact with one another.
This means they also need to be written and organised more efficiently. I feel I'm lacking some typical computer science knowledge on this matter and wanted to ask a bit around on what the best way of doing it is.
- Let's say I deployed 4 TF models that essentially do the same thing but are dedicated to different markets and their local specificities. However, what I had to build on top was a preprocessing endpoint that would accept the request and prepare it in order then to call one of the four respective endpoints. So within the preprocessing API I have some code that prepares the data and calls the TF model, retrieves the response and passes it on. I thought the best way to tackle this is the following:
-
at the beginning of my API code I'm loading all necessary data that is shared across those endpoints to decrease initial load time
-
each TF model call for each country has it's dedicated endpoint (there will be 4 but currently are 2 as shown below)
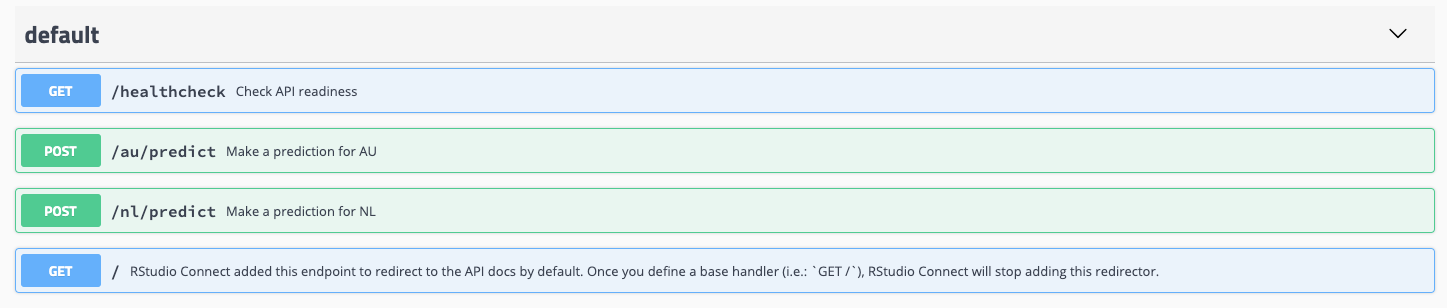
Question : is that the right way of doing it or should perhaps each preprocessing endpoint for each TF model be a separate API? What's the best way of structuring this?
- Let's say that additionally to those TF models the preprocessing endpoint should also make a call to another API (let's call it Y) in order for it to make some additional computations on the same data and get back the response from Y in order to integrate it in the main preprocessing response. The Y API is a separate service as it also could be called independently of the main preprocessing endpoint.
Two questions on that design:
-
at the moment API Y is always called when the main preprocessing endpoint it called. How to best structure the endpoint path and the underlying code efficiently in order to give a client the choice of with/ without API Y response? I'm more thinking in terms of not copying & maintaining the same code etc., would using filters here be the right choice if the TF model (for one of the markets) will always be called and then depending on the request it would be routed to an endpoint?
-
a more general one is if this kind of nesting of services is a good idea. I have a feeling that I'm loosing visibility on timing my services. Is that common practice what I'm doing or is there a better way?
Thank you!