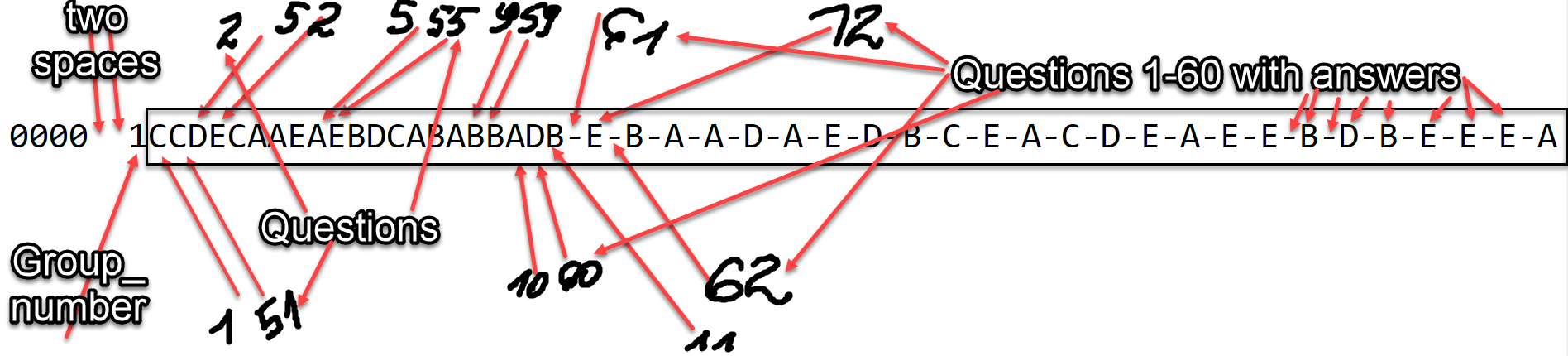
This is a result of a test for one candidate. I have results of 100 candidates.
In test we have 60 questions and the answers are from A to E. They are placed on test-card in two columns, from 1-50 and 51-100 and this is why I have "-" (dashes) in my data. This is how testing machine spits out results into a *.txt file. It scans it columnwise I suppose. First four digits are numerical codes for candidate, then because two columns are left empty I have two spaces , then I have group number (1 or 2) and then I have answers to questions from 1-60.
* are here to mark what machine did not recognize properly.
There are much more elegant ways especially when it comes to automating this, but maybe this would help get you started. The idea is to use substr to extract the nth element from a string and place it into the column you want.
#Using first string provided in example
line1 <- c("0001 2EDBACCBDCEDDB*BACCADB-A-C-A-A-E-A-*-E-B-C-B-C-C-D-A-C-A-E-B-C-B-D-C-A-A-A-E-A-B-C-E-A-E-E-A-A-D-B-E-")
#Construct the dataframe with appropriate column names
def_not_homework <- as.data.frame(matrix(ncol=11))
colnames(def_not_homework) <- c("code_number_of_candidate", "Space_1", "Space_2", "Group_Number", "Question_1", "Question_2", "Question_3", "Question_4", "Question_5", "Question_6", "Question_7")
#The first four characters of the string get placed in column "Code_number_of_candidates"
#The 5th character gets put into Space_1
#etc, etc
def_not_homework$code_number_of_candidate <- substr(line1, 1,4)
def_not_homework$Space_1 <- substr(line1, 5,5)
def_not_homework$Space_2 <- substr(line1, 6,6)
def_not_homework$Group_Number <- substr(line1, 7,7)
Hope this at least points you in the right direction
Hi @Andrzej,
This code should produce the nice tidy dataframe output that you need:
dat <- c("
0001 2EDBACCBDCEDDB*BACCADB-A-C-A-A-E-A-*-E-B-C-B-C-C-D-A-C-A-E-B-C-B-D-C-A-A-A-E-A-B-C-E-A-E-E-A-A-D-B-E-
0002 2EEBACBBDCEDDB*BACCADB-A-C-A-A-D-A-D-E-B-C-B-C-B-D-A-C-A-E-B-*-B-D-C-A-A-A-E-A-B-C-E-A-E-E-A-A-D-B-A-
0223 2EBBACEBDCEDDBABAC*ADB-A-E-A-A-D-B-D-E-B-*-B-C-C-D-A-C-A-E-B-C-B-D-C-A-E-A-E-A-B-C-E-A-E-E-A-B-D-B-C-
0004 2EDBACC*DCEDDB*BACCADB-A-C-B-A-C-A-D-E-B-C-B-C-B-D-A-C-*-E-B-C-B-D-C-A-A-A-E-A-C-C-E-A-E-E-A-A-D-B-B-
0285 2EABA*CBDCEDDBEBACCADB-A-D-A-A-D-A-D-E-B-C-B-C-C-D-A-C-A-E-B-C-B-D-C-D-A-A-E-A-B-C-E-A-E-E-A-A-D-B-B-
")
library(readr)
datin <- read_lines(file=dat, skip=1)
library(stringr)
tmp1 <- str_replace_all(datin, " ", "")
tmp2 <- str_replace_all(tmp1, "-", "")
tmp2
#> [1] "00012EDBACCBDCEDDB*BACCADBACAAEA*EBCBCCDACAEBCBDCAAAEABCEAEEAADBE"
#> [2] "00022EEBACBBDCEDDB*BACCADBACAADADEBCBCBDACAEB*BDCAAAEABCEAEEAADBA"
#> [3] "02232EBBACEBDCEDDBABAC*ADBAEAADBDEB*BCCDACAEBCBDCAEAEABCEAEEABDBC"
#> [4] "00042EDBACC*DCEDDB*BACCADBACBACADEBCBCBDAC*EBCBDCAAAEACCEAEEAADBB"
#> [5] "02852EABA*CBDCEDDBEBACCADBADAADADEBCBCCDACAEBCBDCDAAEABCEAEEAADBB"
library(tidyr)
cols_out <- c("id", "group", paste0("A", 1:60))
data.frame(string = tmp2) %>%
separate(col=string,
into=cols_out,
sep = c(4, 5, 6:65)) %>%
replace(., . =="*", NA)
#> id group A1 A2 A3 A4 A5 A6 A7 A8 A9 A10 A11 A12 A13 A14 A15 A16 A17
#> 1 0001 2 E D B A C C B D C E D D B <NA> B A C
#> 2 0002 2 E E B A C B B D C E D D B <NA> B A C
#> 3 0223 2 E B B A C E B D C E D D B A B A C
#> 4 0004 2 E D B A C C <NA> D C E D D B <NA> B A C
#> 5 0285 2 E A B A <NA> C B D C E D D B E B A C
#> A18 A19 A20 A21 A22 A23 A24 A25 A26 A27 A28 A29 A30 A31 A32 A33 A34 A35
#> 1 C A D B A C A A E A <NA> E B C B C C D
#> 2 C A D B A C A A D A D E B C B C B D
#> 3 <NA> A D B A E A A D B D E B <NA> B C C D
#> 4 C A D B A C B A C A D E B C B C B D
#> 5 C A D B A D A A D A D E B C B C C D
#> A36 A37 A38 A39 A40 A41 A42 A43 A44 A45 A46 A47 A48 A49 A50 A51 A52 A53 A54
#> 1 A C A E B C B D C A A A E A B C E A E
#> 2 A C A E B <NA> B D C A A A E A B C E A E
#> 3 A C A E B C B D C A E A E A B C E A E
#> 4 A C <NA> E B C B D C A A A E A C C E A E
#> 5 A C A E B C B D C D A A E A B C E A E
#> A55 A56 A57 A58 A59 A60
#> 1 E A A D B E
#> 2 E A A D B A
#> 3 E A B D B C
#> 4 E A A D B B
#> 5 E A A D B B
These question are a bit jumbled so I would like to kindly ask you how to first:
make a alternate sequence form 1 do 100 that will give a vector: Question_1, Question_51, Question_2, Question_52, Question_3, Question_53, Question_4, Question_54, Question_5, Question_55 and so on up to Question_50 and Question_100 ?
Is it possible to make such an interchangeable sequence ?
It's probably possible to do this easier, but converting to long format and back should work:
# data frame from previous answer:
mydata <- data.frame(string = tmp2) %>%
separate(col=string,
into=cols_out,
sep = c(4, 5, 6:65)) %>%
replace(., . =="*", NA)
# new code:
sequence <- c()
for(i in 1:30){ #number depending on number of questions: maybe needed to change this to 100?
sequence <- c(sequence, i, i+30)
}
new_colnames <- c("id", "group", sequence)
colnames(mydata) <- new_colnames
library(tidyr)
mylongdata <- mydata %>%
pivot_longer(names_to = "question.no",
values_to = "answer", c(3:62)) %>% ## change total number of columns (in here 62) if necessary
arrange(id, as.numeric(question.no))
# you can get it back to wide format now if desired:
mywidedata <- mylongdata %>%
pivot_wider(names_from = question.no, values_from = answer,
names_prefix = "Question_")