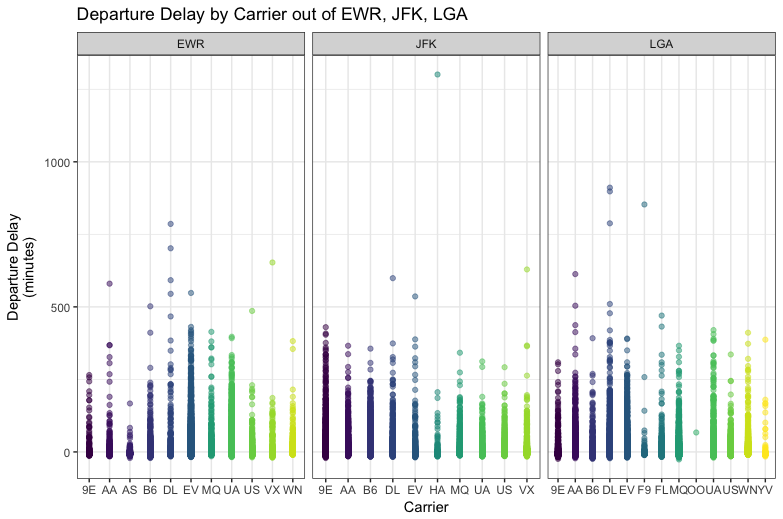
But then I thought, means aren't really a good summary stat I should base my decision off of. So I started plotting my data
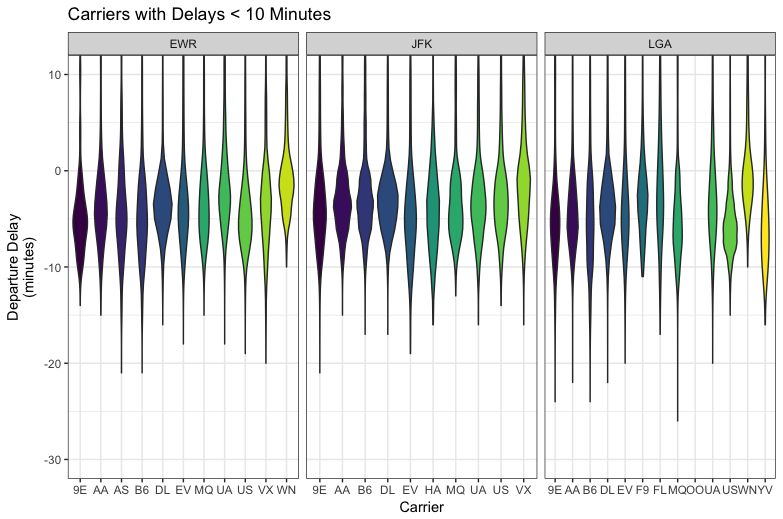
I can see there are quite a few outliers but my thought is to keep them in the dataset as they provide valuable information on how badly a departure can be delayed at times. After getting a glimpse of the entire dataset, I wanted to look closer at departure times that are negative (meaning departed early) or around zero.
These plots are valuable but don't really make it obvious which airlines and airport would be the best for me to take given all the information I have. My next thought is to estimate the CDF for each airlines departure delay and then compute P(X < 0). At that point I can then select the airlines that have the highest probability of having a departure delay of at most zero.
My question is two parts:
Is this sound statistical reasoning? Is there a test I can perform that would be better? I Really would just like some guidance on thinking this problem through.
If this is sound statistical thinking, are there any resources you can direct me towards that would teach me how to implement it in R?
Proportional odds logistic regression and quantile regression come to mind. I might use quantized regression to estimate the predicted median delay and make my decision based on those values.
You could use ANOVA (or Kruskall-Wallace since it looks like your data may not be normally distributed) and that will tell you whether any of the airlines vary significantly without losing control of your alpha level. If that test shows significance (i.e. there is significant variation between any of the distributions) then you can do pairwise comparisons (t-test or mann-whitney) between the data sets to see if there are significant differences between each dataset.
Granted this is not the most complex method but sometimes simple is better!
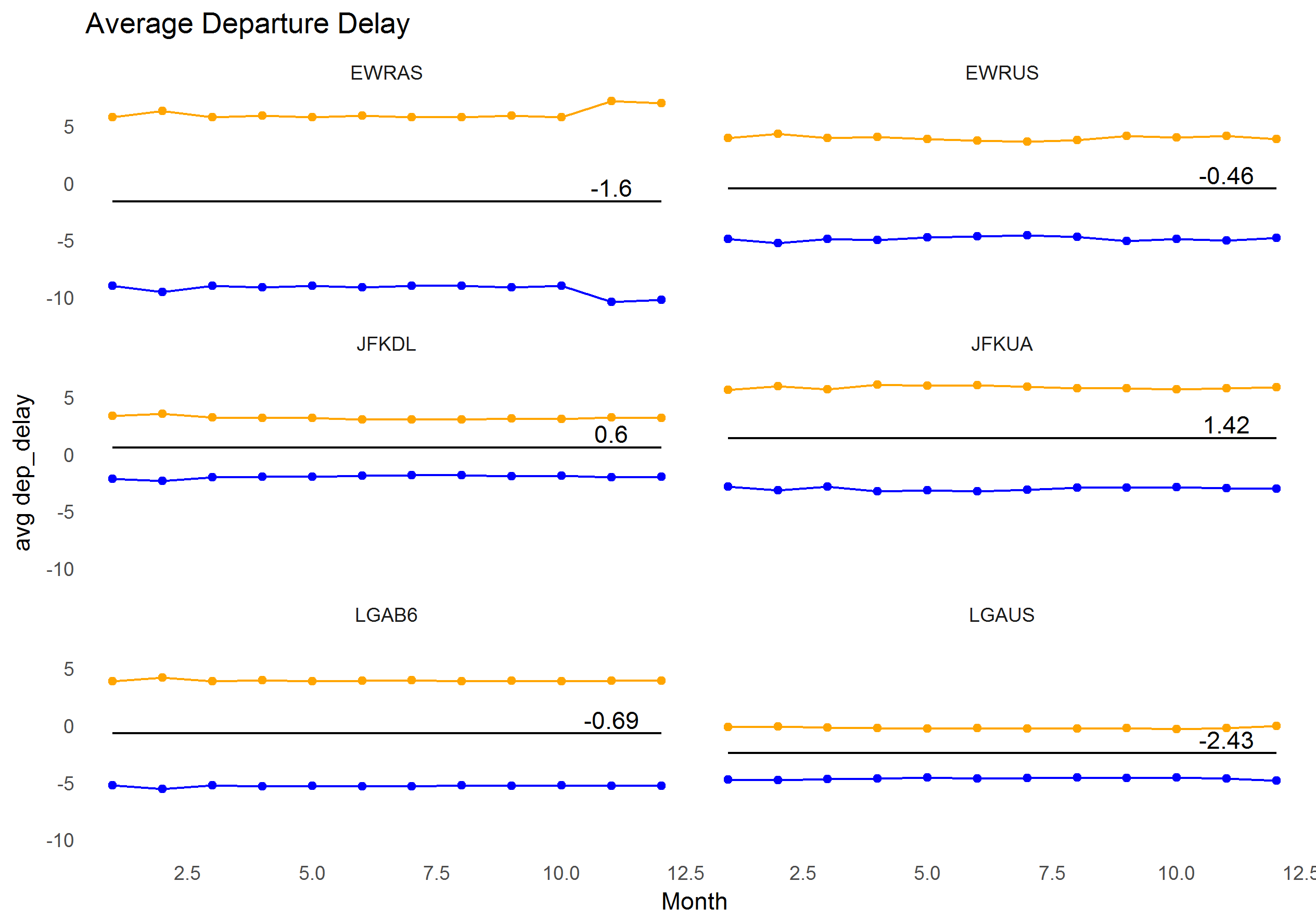
I used the qicharts2 package ( creating a xbar chart for all origin~carrier combos).
The dark centre line represents the mean dep_delay, the orange = the Upper Control Limit and the blue the Lower Control Limit.
Ideally you're looking for the lowest average delay, with the narrowest limits around that.
The origin~carrier combo with the lowest mean departure delay, plus the narrowest upper/ lower limits, is LGA~US.
The added advantage of this is the data is plotted over time, so you can see what the "trends" are, rather than boxplots/ violin plots where you can see the distribution but have no way of knowing what the recent performance is like.
Once qicharts2 has done the hard work, its over to dplyr and ggplot 2 for some final filtering and plotting. I've left these pretty rough and ready but you get the idea.
Hopefully this pans out with whatever results you might achieve through other means..