You can use the adorn_totals() function, which is in the janitor package. Here, I provide two solutions: one with base R and one with the purrr package. Let me know if you have more questions:
# Load the janitor package
library(janitor)
# Create sample data
set.seed(1)
d <- lapply(1:2, function(x) data.frame(province = sample(6, size = 3), Y = rnorm(3)*100, Z = rnorm(3)* 100))
# Solution using base R
lapply(d, function(x) adorn_totals(dat = x, where = "row"))
[[1]]
province Y Z
6 -137.70596 -5.93134
2 -41.49946 110.00254
1 -39.42900 76.31757
Total -218.63441 180.38877
[[2]]
province Y Z
6 -83.20433 -156.37821
3 -116.65705 115.65370
1 -106.55906 83.20471
Total -306.42044 42.48021
# Solution using the tidyverse
library(purrr)
map(d, ~ adorn_totals(.x, where = "row"))
[[1]]
province Y Z
6 -137.70596 -5.93134
2 -41.49946 110.00254
1 -39.42900 76.31757
Total -218.63441 180.38877
[[2]]
province Y Z
6 -83.20433 -156.37821
3 -116.65705 115.65370
1 -106.55906 83.20471
Total -306.42044 42.48021
Actually, even though I answered the question with adorn_totals(), I would say that adding a row for total and for percentage in your data is not the best way to do things. I understand that you may want to do it to present your results, in which case I recommend the gt package for creating tables with summary rows. The following article will teach you how to do it: https://gt.rstudio.com/articles/creating-summary-lines.html However, you should not add total and percentage rows to your data.
Also, I have a question about the percentage value that you are expecting. Could you please tell me what percentage values you are expecting given your examples above?
@gueyenono, Thank you for writing the code which I am looking for. Just want to know if I have a different number of columns in the list. I do not know you change the below code to apply for all columns in each data frame in the list.
Here we have two columns( Y, Z) in both data frames in the list. My list data frame has different numbers of columns. I just added a screenshot of my list
Yes, "province" is the first column for all. Your code is great. It is the code that I am looked for, just I do not know to change this line of code: sapply(x[, c("Y", "Z")], sum). As you wrote c("Y", "Z") my list has a different number of columns. Instead of c("Y", "Z") should be something to represent all columns. Thank you.
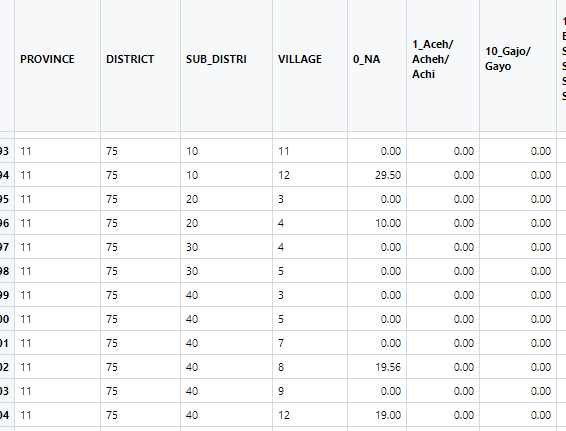
@gueyenono there is "province, district, sub_district, and village" should not get the total and percentage.
The data frame look like this :
I used the following code :
lapply(d, function(x){
last_row <- nrow(x)
total <- sapply(x[, -4)], sum)
pct <- total / sum(total)
x[last_row+1, ] <- c("Total", total)
x[last_row+2, ] <- c("Percentage", pct)
x
})
Instead "-1 " -4 but did not work.
Thank sir for all your time and solving my problems.
Is it possible to move the percentage row to top ( after column names) and total row to be in the second row of each data frame in the list?