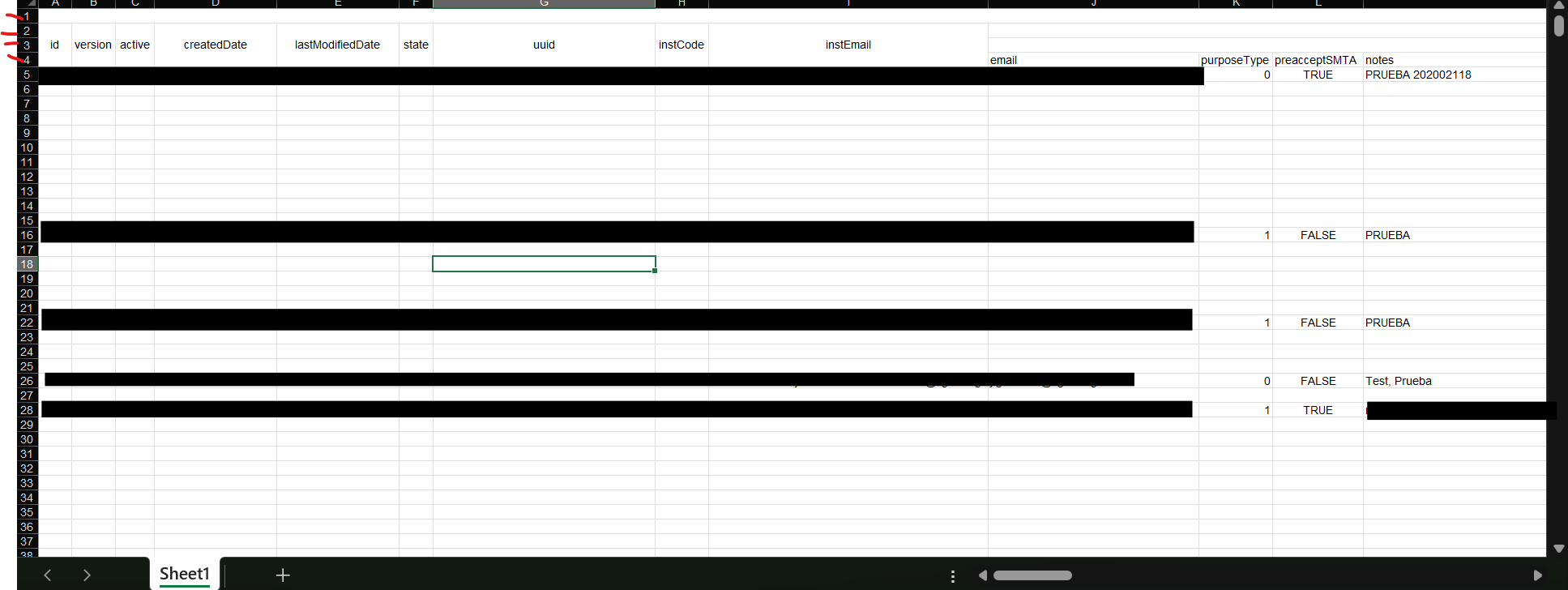
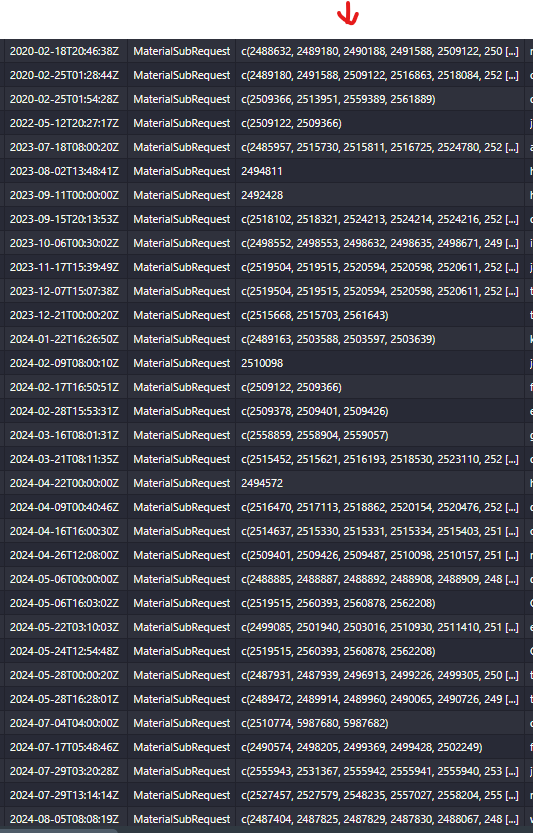
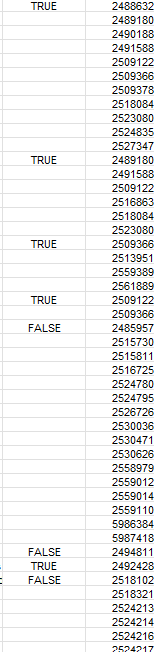
Currently, I need to transform the JSON file into a more accessible format, such as a data.frame or an Excel file. My goal is to organize the headings in a single row, as the first three rows of the file contain header information distributed in different fields.
Additionally, I used a tool (free page) that generated headings occupying several cells, which I want to avoid. I would like to consolidate the headings into a single row that contains all the headings in a clear and organized manner.
Thank you for your suggestion,
I just don't know how to put a dput from a JSON file.
When I use the tool to convert from JSON to excel, I get the above image. If you notice well, the headers are in the first 4 rows (red). I would like with R to be able to adjust it so that all the headers are in the first row as well as a df.
I didn't quite get what you meant by the first three rows containing header information, but I think you can get pretty far along to where you'd like to go with the jsonlite package. Your data looks like it's coming from a REST API or something, so you'll want the $content part of that nested list.
If you don't flatten it, the body column will be nested, which may be your preference here.
Also, a friendly suggestion: I would try to provide a minimal example of the structure you're trying to parse instead of linking files with potentially real personal data in them.
That depends completely of your json doc structure, but in short term, u can use a function like fromJSON() from jsonlite. Even if u do this, if ur JSON doc have many childs, some of the fields can't be passed to an excel document, so for this cases u can use unnest() from tidyr to ungroup the lists in ur doc. Suppose the following estructure:
library(jsonlite)
library(tidyr)
x <- '
[{
"quiz": {
"sport": {
"q1": {
"question": "Which one is correct team name in NBA?",
"options": [
"New York Bulls",
"Los Angeles Kings",
"Golden State Warriros",
"Huston Rocket"
],
"answer": "Huston Rocket"
}
},
"maths": {
"q1": {
"question": "5 + 7 = ?",
"options": [
"10",
"11",
"12",
"13"
],
"answer": "12"
},
"q2": {
"question": "12 - 8 = ?",
"options": [
"1",
"2",
"3",
"4"
],
"answer": "4"
}
}
}
}]'
class(x) <- "json"
question options answer question1 options1 answer1 question2 options2 answer2
<chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
1 Which one is correct team name in NBA? New York Bulls Huston Roc… 5 + 7 = ? 10 12 12 - 8 =… 1 4
2 Which one is correct team name in NBA? Los Angeles Kings Huston Roc… 5 + 7 = ? 11 12 12 - 8 =… 2 4
3 Which one is correct team name in NBA? Golden State Warriros Huston Roc… 5 + 7 = ? 12 12 12 - 8 =… 3 4
4 Which one is correct team name in NBA? Huston Rocket Huston Roc… 5 + 7 = ? 13 12 12 - 8 =… 4 4
that's not the best way to fix this, but should works for u
fromJSON(my_json_file) |>
tidyr::unnest() |>
tidyr::unnest() |>
tidyr::unnest() |>
tidyr::unnest()
# Error in UseMethod("unnest") :
# no applicable method for 'unnest' applied to an object of class "list"
# In addition: Warning message:
# `cols` is now required when using `unnest()`.
# ℹ Please use `cols = c(content, sort, filter)`.
I think you could achieve this by (maybe as a first step) cleaning up the list column to get rid of anything you don't want to retain, and then using tidyr::unnest_longer() to pivot those values. Alternatively, you could use tidyr::hoist() and "lift" out what you want from that nested list column, drop it, and then perform the pivot longer operation.
Have you tried using any specific R packages, such as jsonlite, tidyjson, or httr, to convert the JSON file into a data frame? If so, were there any issues or challenges with them?