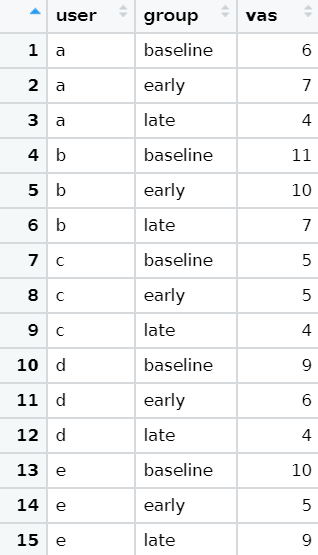
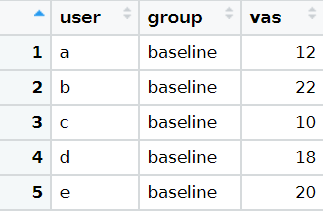
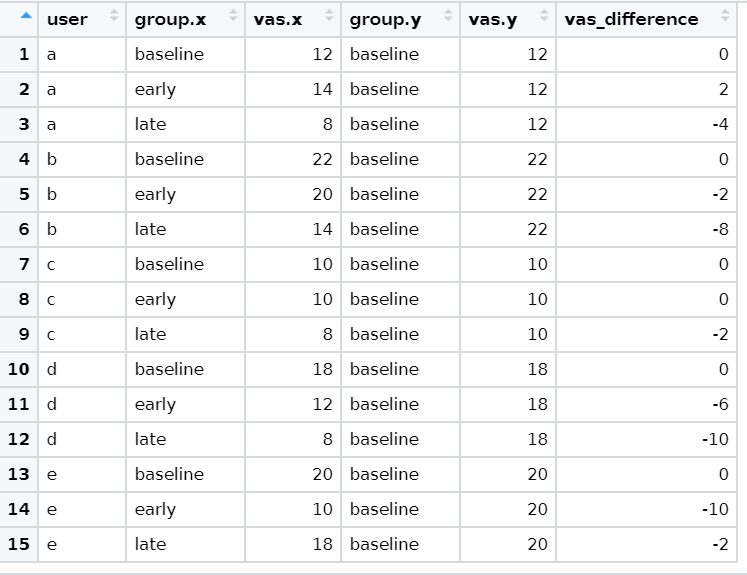
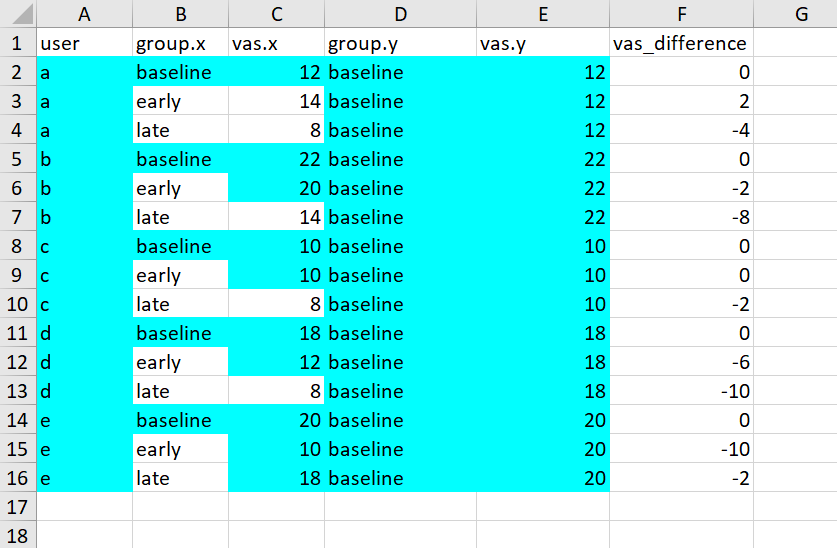
I would like to understand how this two dataframes (one of them is a subset from the other) can be joined together if a first dataframe has got 15 rows:
vas = data_frame(
user = rep(letters[1:n_users], each = 3),
group = rep(c("baseline", "early", "late" ),n_users),
vas = round(rgamma(n_users*3, 10,1.4 ))
)
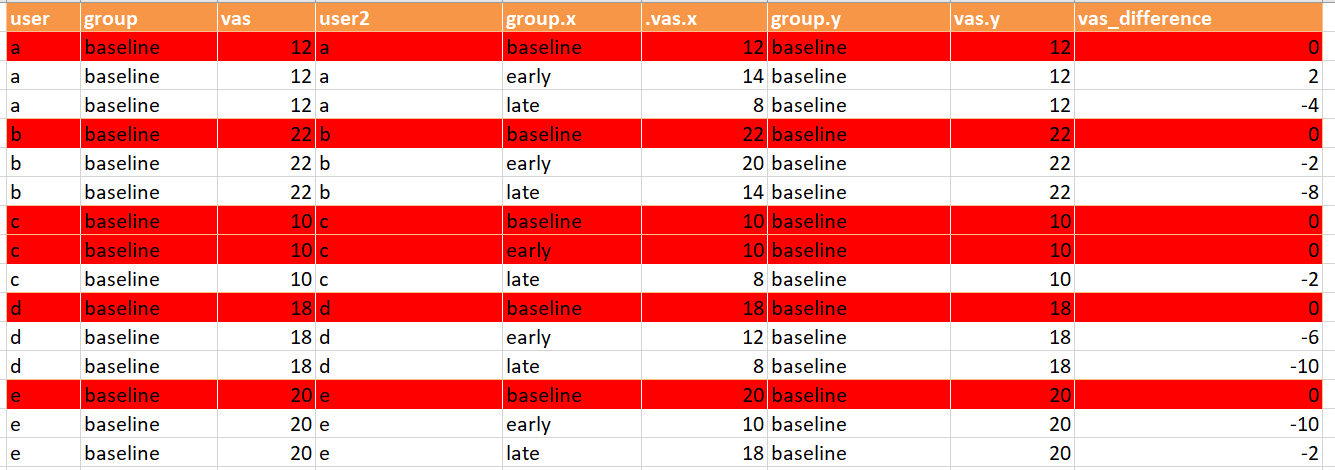
I apologize fort a naive question, but would it be possible to see where all cells (values) from
"vas_baseline" are situated now in "vas_with_diff" ? Sort of like maybe conditional formatting in an Excel way.
What would have happened if "vas_baseline" had more columns than "vas_1" ?
The generation of NA values as a result of a join is dependent on the joining keys, not the number of rows in the data frames being joined.
In the example, vas_1 and vas_baseline are being left joined using only the user variable. So, the variables in the right data frame (vas_baseline) will be joined to vas_1 wherever a match is found for user. Since both data frames contain all 5 possibilities (a to e), there are no NA values in the result.
If instead you added group to the join criteria, then you would get NA values, since the vas_baseline data frame contains only one group type.
left_join(vas_1, vas_baseline, by = c("user", "group"))
# A tibble: 15 x 4
user group vas.x vas.y
<chr> <chr> <dbl> <dbl>
1 a baseline 14 14
2 a early 14 NA
3 a late 22 NA
4 b baseline 12 12
5 b early 10 NA
6 b late 18 NA
7 c baseline 22 22
8 c early 14 NA
9 c late 16 NA
10 d baseline 16 16
11 d early 10 NA
12 d late 10 NA
13 e baseline 16 16
14 e early 16 NA
15 e late 26 NA
I don't think there is a way to highlight matched rows (if I understand correctly what you mean). The rows which returned NA for the variables in the right data frame are the unmatched rows.