I am trying to predict how likely it is that casual customers will convert into memberships in R. I know that I can either use logistic regression or a decision tree but need help after I upload the dataset onto the console.
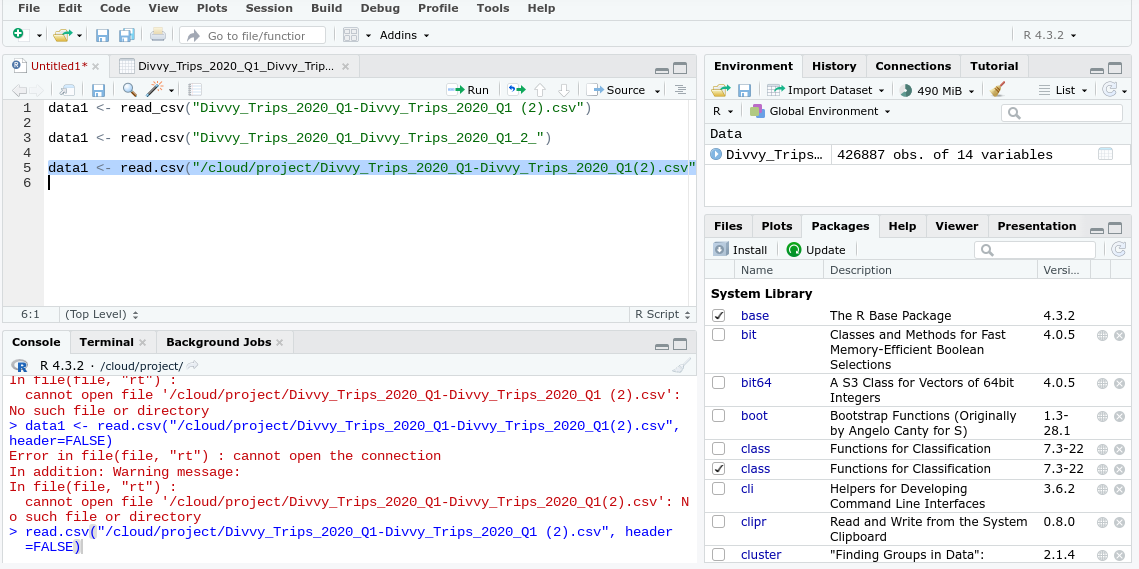
Error Message - Error in file(file, "rt") : cannot open the connection
In addition: Warning message:
In file(file, "rt") :
cannot open file '/cloud/project/Divvy_Trips_2020_Q1-Divvy_Trips_2020_Q1 (2).csv': No such file or directory
Why is it stating that no such file is in the directory if I uploaded it and imported it already?
Using absolute file paths is usually a bad idea in R, the error message you are getting can only mean that you are not specifying the file path correctly. We can't see your environment so we can't tell you what the correct file path is but I think you should look into using a relative file path instead.
I'm sorry I fairly new to R. I am not understanding. I thought I had to use the exact file name to import the dataset to begin working on it. Here I have included a screenshot of the environment panel. Thank you for explaining.
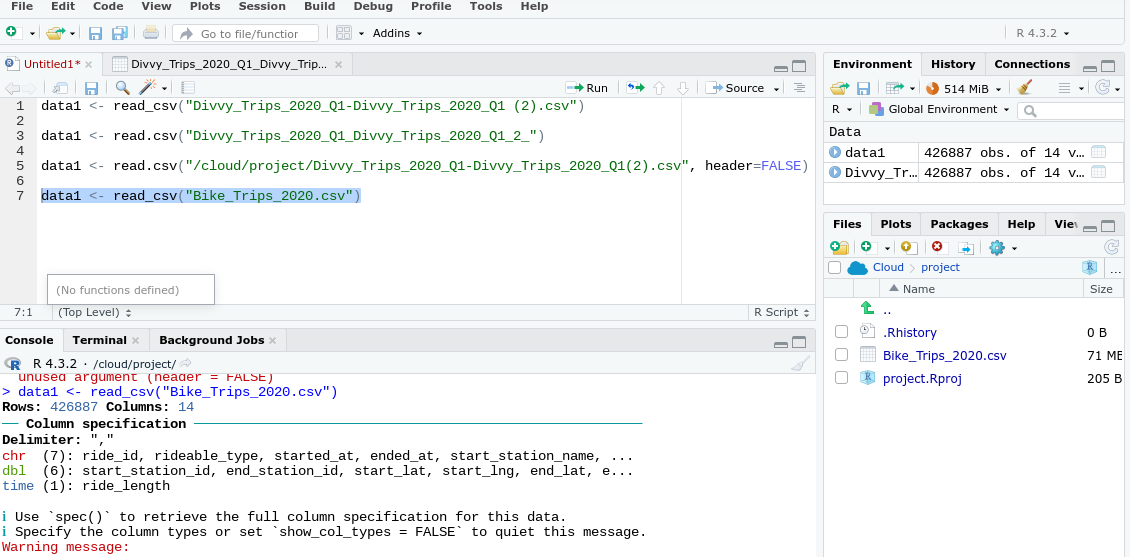
You should use a relative file path to the csv file like in the first line of code you are showing but maybe you are dealing with a problematic file name. Try changing the file name to something safer (with out parentheses). Or even better use the UI tools to import the file using a dialog box, that way you don't need to manually type anything
Use spec() to retrieve the full column specification for this data. Specify the column types or set show_col_types = FALSE to quiet this message.
Warning message:
One or more parsing issues, call problems() on your data frame for details,
e.g.:
dat <- vroom(...)
problems(dat)
Here's a screenshot so you can better see everything.
Hello All, next I am trying to set up the linear regression model in R.
Ultimately my goal is to predict how many casual customers will convert to memberships in 2 years.
Firstly, I am inputting the linear regression as such:
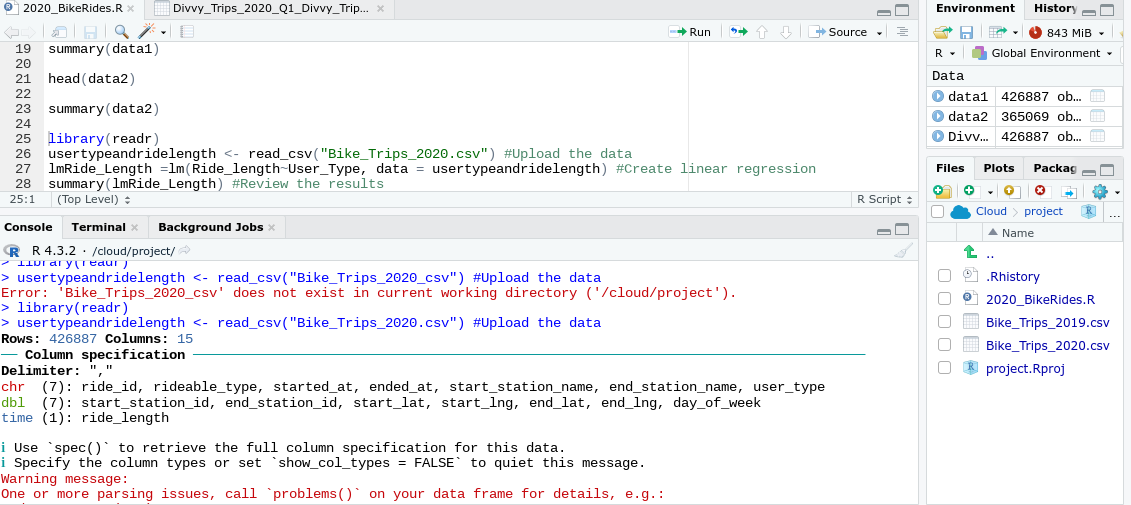
library(readr)
usertypeandridelength <- read_csv("Bike_Trips_2020.csv") upload the data
lmRide_Length =lm(Ride_length~User_Type, data = usertypeandridelength) #Create linear regression
summary(lmRide_Length) #Review the results
I received an error message:
library(readr)
usertypeandridelength <- read_csv("Bike_Trips_2020_csv") upload the data
Error: 'Bike_Trips_2020_csv' does not exist in current working directory ('/cloud/project').
library(readr)
usertypeandridelength <- read_csv("Bike_Trips_2020.csv") upload the data
Rows: 426887 Columns: 15
── Column specification ────────────────────────────────────────────────────────────────────────────────────
Delimiter: ","
chr (7): ride_id, rideable_type, started_at, ended_at, start_station_name, end_station_name, user_type
dbl (7): start_station_id, end_station_id, start_lat, start_lng, end_lat, end_lng, day_of_week
time (1): ride_length
Use spec() to retrieve the full column specification for this data. Specify the column types or set show_col_types = FALSE to quiet this message.
Warning message:
One or more parsing issues, call problems() on your data frame for details, e.g.:
dat <- vroom(...)
problems(dat)
lmRide_Length =lm(Ride_length~User_Type, data = usertypeandridelength) #Create linear regression
Error in eval(predvars, data, env) : object 'Ride_length' not found
Where am I going wrong, I am following the instructions listed on Data camp, verbatim.
Error message: Use spec() to retrieve the full column specification for this data. Specify the column types or set show_col_types = FALSE to quiet this message.
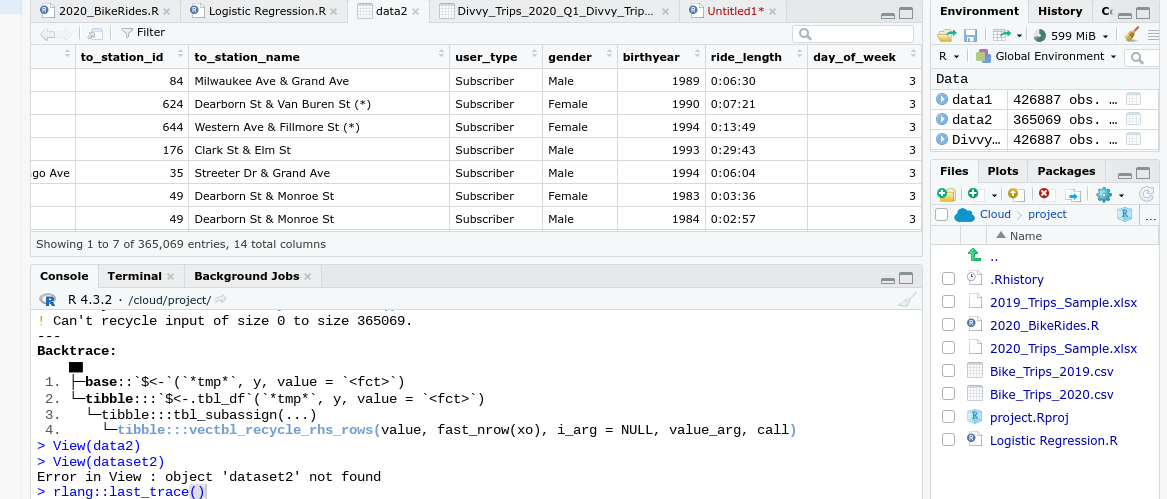
dataset2$y = as.factor(dataset2$y)
Error in $<-:
! Assigned data as.factor(dataset2$y) must be compatible with existing data. Existing data has 365069 rows. Assigned data has 0 rows. Only vectors of size 1 are recycled.
Caused by error in vectbl_recycle_rhs_rows():
! Can't recycle input of size 0 to size 365069.
Run rlang::last_trace() to see where the error occurred.
Warning message:
Unknown or uninitialised column: y.
rlang::last_trace()
<error/tibble_error_assign_incompatible_size>
Error in $<-:
! Assigned data as.factor(dataset2$y) must be compatible with existing data. Existing data has 365069 rows. Assigned data has 0 rows. Only vectors of size 1 are recycled.
Caused by error in vectbl_recycle_rhs_rows():
! Can't recycle input of size 0 to size 365069.