Very new to R (learned basics in Google DA Certificate), so please forgive. I am using dplyr.
I have a dataframe with the following structure and 112 rows:
measure avg delta epsum flora light perry phoenix sans tim winn yoda
1 0.984 1 0.97 1 1 1 1 1 1 1 0.87
2 0.997 1 1 0.97 1 1 1 1 1 1 1
3 0.97 0.97 0.97 0.97 0.97 0.97 0.97 0.97 0.97 0.97 0.97
4 1 1 1 1 1
5 0.983 1 0.98 1 0.96 1 0.99 1 0.93 0.97 1
6 0.981 1 1 0.96 0.94 0.96 1 1 0.95 1 1
7 0.996 1 1 1 0.97 1 0.99 1 1 1 1
8 0.977 0.93 1 0.98 0.99 1 0.99 1 1 1 0.88
9 1 1 1 1 1 1 1 1 1 1 1
10 0.907 1 0.93 0.85 1 0.69 0.9 1 0.87 1 0.83
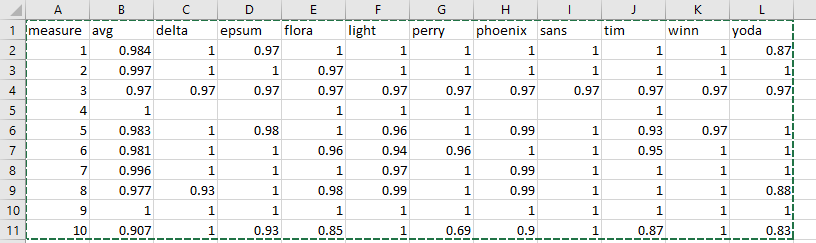
I am trying to find a way to get a summary with a count of every variable (column) that has a score greater than .85
I have been able to do that with the count() function, but only for one variable at a time. What I want, is to get one with all the variables, that I can then make a dataframe and plot it.
Ideally, I would want to se something like this:
measure avg delta epsum flora light perry phoenix sans tim winn yoda
1 0.984 1 97 65 73 85 58 96 103 56 96 88
where I get the number of rows where each variable was greater than .85
Is that possible?