It feels terrific to publish my first post in the RStudio community.
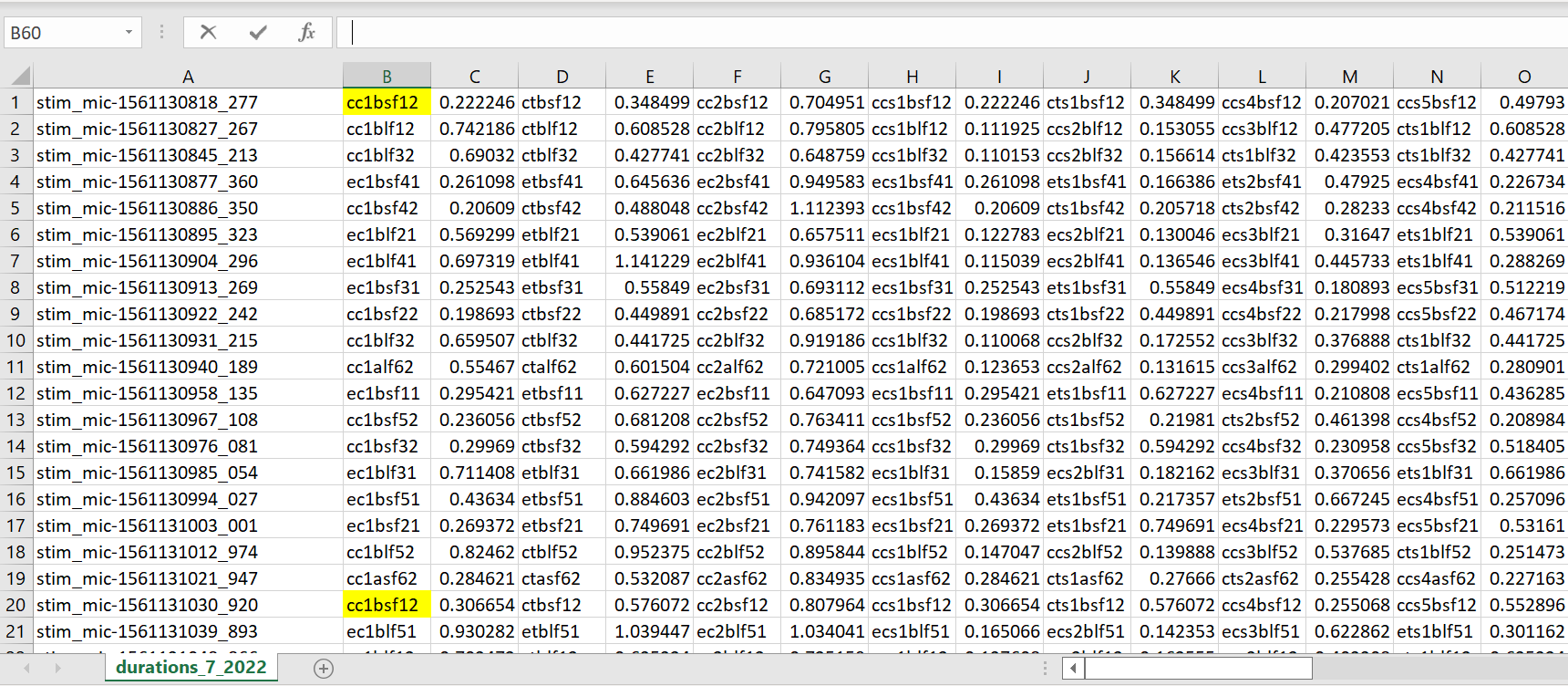
The attached spreadsheet has a strange format. I would need to reorganize it to do statistical analyses.
This spreadsheet is the output of a Praat script which measures the duration of labeled segments in an audio file.
Each label (for example "cc1bsf12" highlighted in the screenshot) occurred a maximum of five times in the audio file.
Ideally, I thought I would have columns with each label as header, like "cc1bsf12"., with the five measures in the column. But I would appreciate hearing from you about whether this is a good idea, and how to do this.
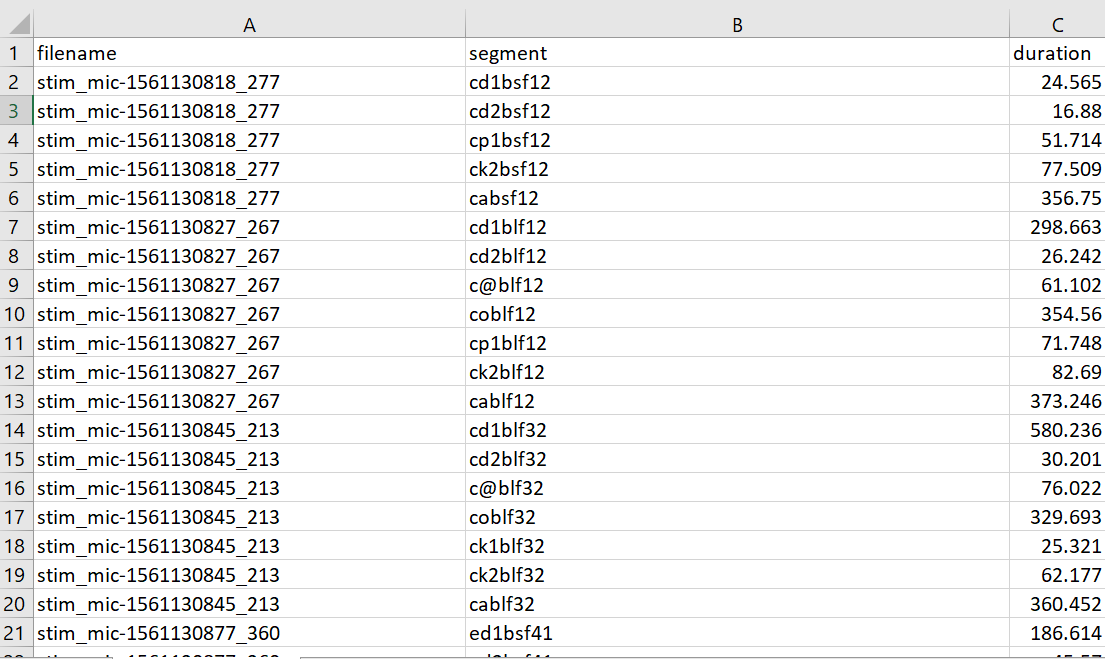
For data processing and further calculations a long format would be more adequate, that would be three columns, file_id, segment and duration. For this you can use tidyr::pivot_longer()
Yes, that's what I meant. It would be closer to a normalized structure.
Yes, you can share a link to it but be aware that some people here do not like downloading random files from the internet for security reasons so you might lower your chances of getting help when compared to providing sample data on a copy/paste friendly format as described in the reprex guide I linked for you before.