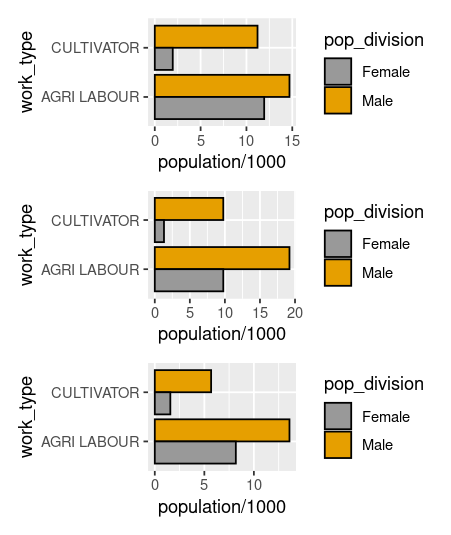
Here is my data:
structure(list(`DT Name` = c("Surat", "Surat", "Surat", "Surat",
"Surat", "Surat", "Surat", "Surat", "Surat", "Surat", "Surat",
"Surat", "Surat", "Surat", "Surat", "Surat", "Surat", "Surat",
"Surat", "Surat", "Surat", "Surat", "Surat", "Surat", "Surat",
"Surat", "Surat", "Surat", "Surat", "Surat"), Name = c("Olpad",
"Mangrol", "Umarpada", "Mandvi", "Kamrej", "Chorasi", "Palsana",
"Bardoli", "Mahuva", "Olpad", "Mangrol", "Umarpada", "Mandvi",
"Kamrej", "Chorasi", "Palsana", "Bardoli", "Mahuva", "Olpad",
"Mangrol", "Umarpada", "Mandvi", "Kamrej", "Chorasi", "Palsana",
"Bardoli", "Mahuva", "Olpad", "Mangrol", "Umarpada"), Level = c("CD BLOCK",
"CD BLOCK", "CD BLOCK", "CD BLOCK", "CD BLOCK", "CD BLOCK", "CD BLOCK",
"CD BLOCK", "CD BLOCK", "CD BLOCK", "CD BLOCK", "CD BLOCK", "CD BLOCK",
"CD BLOCK", "CD BLOCK", "CD BLOCK", "CD BLOCK", "CD BLOCK", "CD BLOCK",
"CD BLOCK", "CD BLOCK", "CD BLOCK", "CD BLOCK", "CD BLOCK", "CD BLOCK",
"CD BLOCK", "CD BLOCK", "CD BLOCK", "CD BLOCK", "CD BLOCK"),
TRU = c("Total", "Total", "Total", "Total", "Total", "Total",
"Total", "Total", "Total", "Total", "Total", "Total", "Total",
"Total", "Total", "Total", "Total", "Total", "Total", "Total",
"Total", "Total", "Total", "Total", "Total", "Total", "Total",
"Total", "Total", "Total"), work_type_by_gender = structure(c(1L,
1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 2L, 2L, 2L, 2L, 2L, 2L, 2L,
2L, 2L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 5L, 5L, 5L), levels = c("MAIN_CL_M",
"MAIN_CL_F", "MAIN_AL_P", "MAIN_AL_M", "MAIN_AL_F", "MAIN_HH_P",
"MAIN_HH_M", "MAIN_HH_F", "MAIN_OT_P", "MAIN_OT_M", "MAIN_OT_F"
), class = "factor"), population = c(11209, 9770, 5685, 20705,
7408, 3883, 3831, 6329, 11563, 1960, 1312, 1569, 4186, 480,
776, 417, 895, 1585, 14695, 19208, 13591, 20419, 18062, 6021,
11750, 23894, 21389, 11936, 9771, 8178), work_type = c("CULTIVATOR",
"CULTIVATOR", "CULTIVATOR", "CULTIVATOR", "CULTIVATOR", "CULTIVATOR",
"CULTIVATOR", "CULTIVATOR", "CULTIVATOR", "CULTIVATOR", "CULTIVATOR",
"CULTIVATOR", "CULTIVATOR", "CULTIVATOR", "CULTIVATOR", "CULTIVATOR",
"CULTIVATOR", "CULTIVATOR", "AGRI LABOUR", "AGRI LABOUR",
"AGRI LABOUR", "AGRI LABOUR", "AGRI LABOUR", "AGRI LABOUR",
"AGRI LABOUR", "AGRI LABOUR", "AGRI LABOUR", "AGRI LABOUR",
"AGRI LABOUR", "AGRI LABOUR"), pop_division = c("Male", "Male",
"Male", "Male", "Male", "Male", "Male", "Male", "Male", "Female",
"Female", "Female", "Female", "Female", "Female", "Female",
"Female", "Female", "Male", "Male", "Male", "Male", "Male",
"Male", "Male", "Male", "Male", "Female", "Female", "Female"
)), row.names = c(NA, -30L), class = c("tbl_df", "tbl", "data.frame"
))
I have plotted a graph which goes like this:
ggplot(data,aes(reorder(work_type, population/1000), population/1000, fill = pop_division,group = Name))+geom_bar( stat='identity',position = position_dodge(),color='black')+
scale_fill_manual(values=c('#999999','#e69F00'))+theme_bw()+labs(x='Work Type', y='Population ( in thousands)',title = 'Distribution of worker type by gender by block in Porbandar dist.',
fill='Gender' )+facet_grid(.~Name)
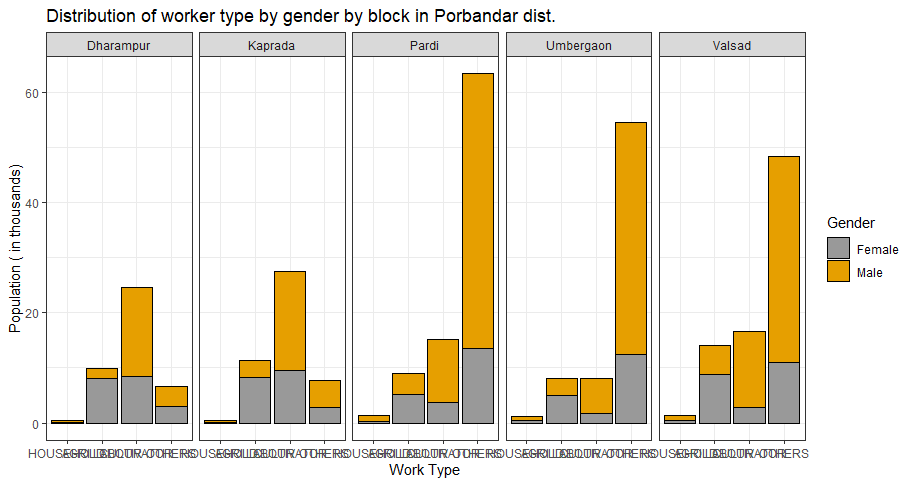
Now the number of different categorical observations in the 'Name' column in the original large dataset are so many that when different facets are plotted the x axis ticks/labels overlap.
How can I convert the x axis tick labels into something smaller so that they do not overlap and provide a legend for it? Any other possible solutions to this?