Hi my name is Alejandro Pereira, research assistant at the Economic and Social Research Institute of the Universidad Católica Andrés Bello, Venezuela. I'm doing an algorithm in the R language to extract data from LinkedIn profiles to apply text mining and identify the skills that are being developed for the labor field.
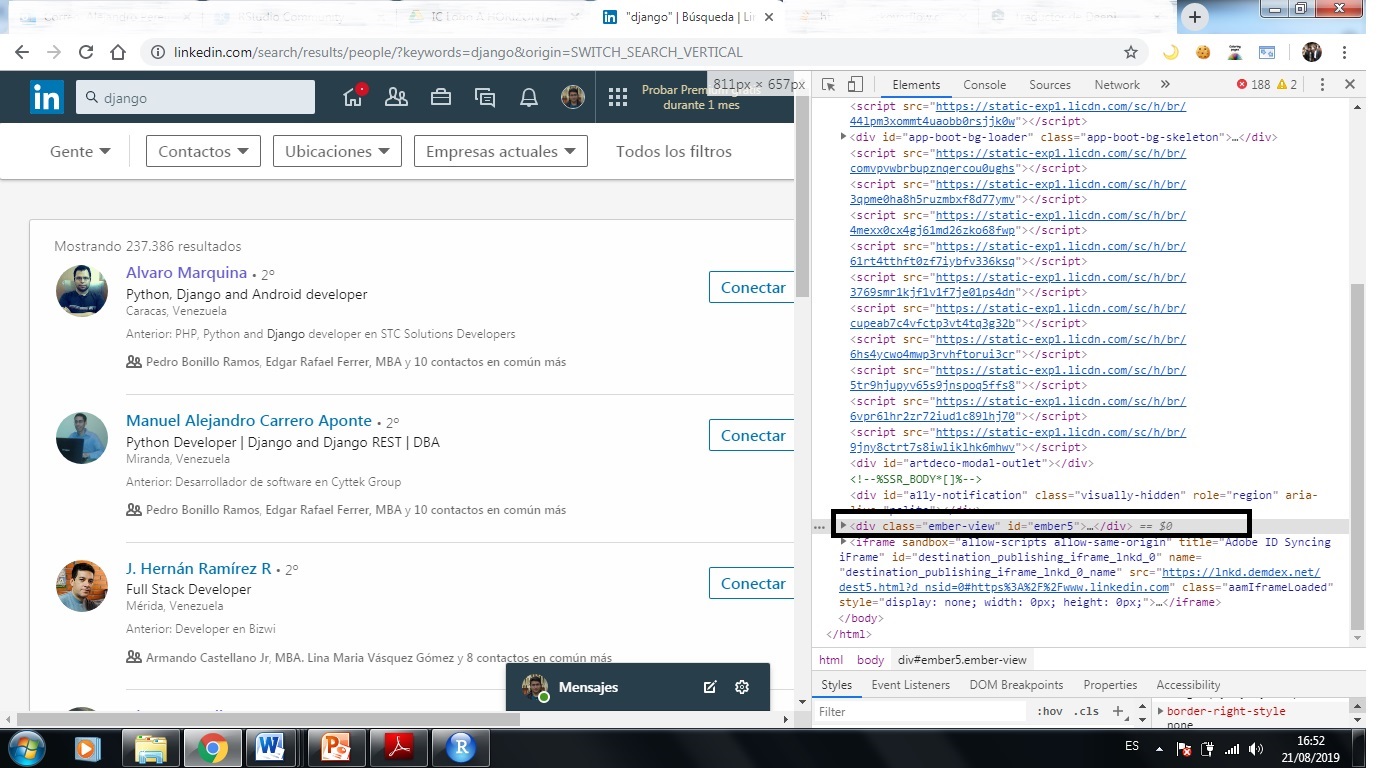
I am using the rvest library of r, I enter the keyword (example: django) in linkedin and I get a link from the search engine to enter it in read_html() . Analyzing the html structure, I want to extract the information from the node
when I introduce the xpath in the html.nodes() function does not get the node.
library(rvest)
library(xml2)
html <- read_html("https://www.linkedin.com/search/results/people/?keywords=django&origin=SWITCH_SEARCH_VERTICAL")
content <- html_nodes(html, "div#ember5")
content
I map the node of class = "div" and I can notice that the node div#ember5 is not there.
html <- read_html("https://www.linkedin.com/search/results/people/?keywords=django&origin=SWITCH_SEARCH_VERTICAL")
content <- html_nodes(html, class ="div")
content
I don't understand why, if anyone can help or explain, I'd appreciate it. Preformatted text
When I download the html at that url with download_html and manually search with Ctrl+F I don't see any instances of the string 'ember-view' or 'ember5', so that might be why html_nodes(html, "div#ember5") isn't finding anything.
Unfortunately I'm not sure why you would be seeing that in your browser's view source but not after downloading the html (someone on that LinkedIn page would probably be able to explain!).
Also, just in case this comes up, I think the syntax for all div elements would be html_nodes(html, css ="div") instead of html_nodes(html, class ="div").
Hi Gabriel, I haven't been able to solve the problem yet.
You're right div#ember5 doesn't appear in the html code it generates, the information is really in the nodes . Even so, when I track the nodes there are some that are hidden. I think it's definitely something from Linkedin's code.
On the other hand, the above code does have errors. It should be html_node (html, css="div")
I'm working on an algorithm that allows me to scrape web to study the skills that are being required in the labor field. When I get the first results I will gladly share them with you.
I think you need to get more cautions with what you are allowed to do when scraping.
It seems the path you want to scrape is not allowed to be scraped with R
robotstxt::paths_allowed("https://www.linkedin.com/search/results/people/?keywords=django&origin=SWITCH_SEARCH_VERTICAL")
#>
www.linkedin.com No encoding supplied: defaulting to UTF-8.
#> [1] FALSE
library(polite)
url <- "https://www.linkedin.com"
session <- bow(url)
#> No encoding supplied: defaulting to UTF-8.
session %>%
nod(path = "search/results/people/?keywords=django&origin=SWITCH_SEARCH_VERTICAL")
#> <polite session> https://www.linkedin.com/search/results/people/?keywords=django&origin=SWITCH_SEARCH_VERTICAL
#> User-agent: polite R package - https://github.com/dmi3kno/polite
#> robots.txt: 1831 rules are defined for 33 bots
#> Crawl delay: 5 sec
#> The path is not scrapable for this user-agent
You'll find a demo in httr that is more recent and show how to connect. The source is here
You'll find it under demo(package = "httr") in your R session. After getting the tokens, using the API following the developers docs should be easy I guess by just finding the endpoints you want.