I am a newbie who is self-teaching R. However, I have run into an issue I can't seem to get an answer to.
I have a data frame (df1) with approximately 40 variables and 300 observations. I have run PCA (prcomp(df1)) on it and then turned the pca$scores into a data-frame (df2).
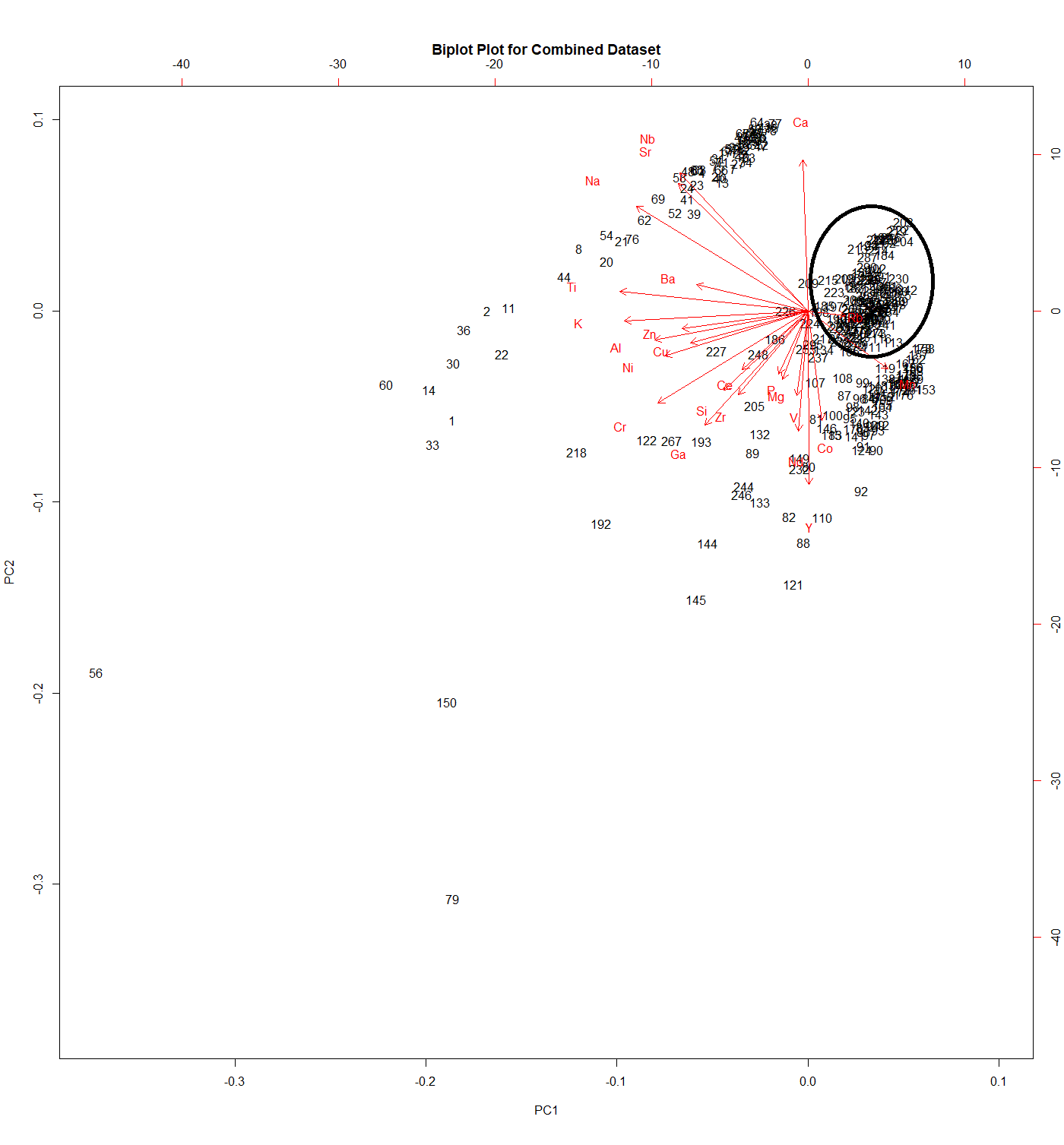
What I want to do now is take the df2 and select data from the df2 by using the values in the first two columns. So if entries in column 1 are between -2 and 2 and values in column 2 are between -5 to 5, I want all of the data in the rows and columns placed into another table.
The reason for this is I want to run PCA again on a subset of the original PCAs data. So I have from the individuals' plots found a cluster of data that is contained within certain PC1 and PC2 corrdinates. See attached graphic.
I am trying to reproduce the double PCA technique discussed in the following paper - "Statistical evaluation of elemental concentrations in shallow-marine deposits (Cretaceous, Lusitanian Basin)" Coimbra et al., 2017.
Please see the FAQ: What's a reproducible example (`reprex`) and how do I do one? Using a reprex, complete with representative data will attract quicker and more answers. It can be really difficult reverse engineering a question from just a description, and screenshots are usually not helpful.
This appears to be a clustering and subsetting question. Have you thought about running a kmeans? Based on your plot you might expect 3 distinct clusters. You can then add the clustering results as an additional vector to your original data frame to then subset on the cluster you wish to perform a pca on.
Example code:
clusters <- kmeans(data, 3)
# Save the cluster number in the dataset as column 'clusters'
data$clusters <- as.factor(clusters$cluster)
#Filter data on cluster 2 using tidyverse
cluster <- data %>%
filter(clusters == "2")