I am writing my PhD thesis in biochemistry and am forced to learn R quickly.
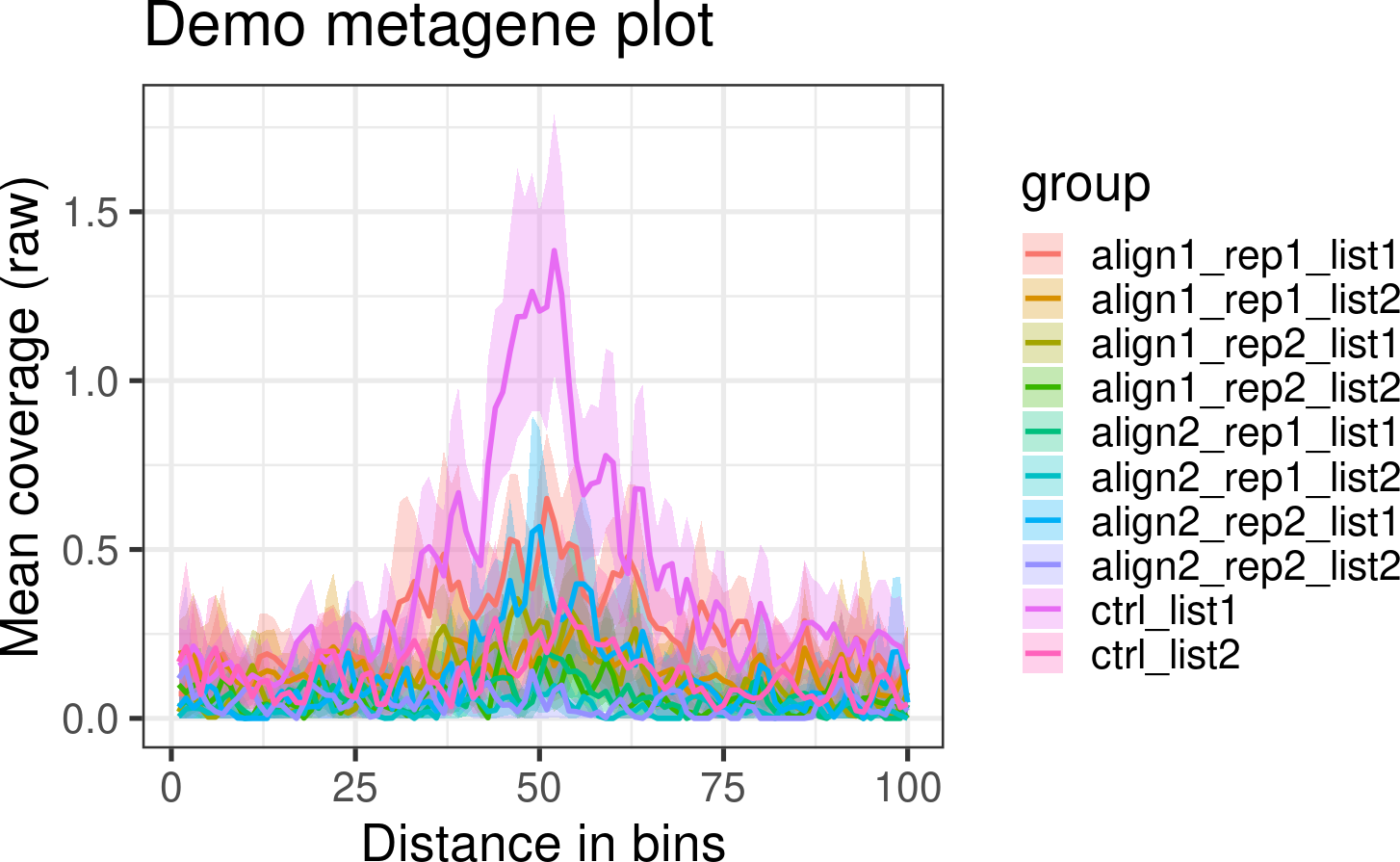
I want to analyse a ChIPseq binding with metagene2 and create a plot like this:
I installed the package via "BiocManager" and the testplot works fine. But right now I am struggling with the basics of the tool. The script which is provided by its vignette is:
'# metagene objects are created by calling metagene2$new and providing
'# regions and bam files:
mg <- metagene2$new(regions = get_demo_regions(),
bam_files = get_demo_bam_files(),
assay='chipseq')
'# We can then plot coverage over those regions across all bam files.
mg$produce_metagene(title = "Demo metagene plot") "
I have no clue how to import my bam files and my regions run the tool on my ChIPseq. Is there any resource to learn these basics in bioconductor, for example, what is mg, what the $ sign is used for and what does "assay" mean?
If you scroll a bit below in the vignette, you get the explanation:
2.1 Specifying alignment files (BAM files)
The paths (relative or absolute) to the BAM files must be provided in a vector. If the vector is named, then those names will be used to refer to the bam files in subsequent steps. Otherwise, metagene2 will attempt to generate appropriate names.
So, let's say the files are in the directory /Users/me/bam_files, you can get their path with:
The provided bam files must be indexed: a file named file.bam, must have an accompanying file.bam.bai or file.bai in its directory.
This indexing can be done with samtools index (from the command line). If you want to stay in R, you can also install Rsamtools to use the function indexBam().
For the regions, see
2.2 Specifying genomic regions
The regions for the metagene analysis can be provided in one of three different formats:
A character vector, containing the paths to bed, narrowPeak, broadPeak or gtf files describing the regions to be used.
A GRanges or GRangesList object defining a set of contiguous regions.
A GRangesList where each element defines a set of regions to be stitched together to be considered as a single logical region.
So depends where your regions come from. I have no experience with ChIP-Seq, I imagine a bed file would be common, in that case you can just use the path to the file. If you use R code to define or edit these regions, you might have them as GRanges or GRangesList objects.
What is hard is that you need to learn both standard "base" R, and the object-oriented "R6" system which is used by this package (though you don't need to understand the R6 system in details, which is very complicated).
Briefly,
x <- 5
defines a variable x with the value 5. So in the vignette code, you define a variable mg which contains a metagene object. You can run mg to take a look at it, and class(mg) to see the class of object ("numeric" for x or "metagene2" for mg).
To create the metagene object, you call a function, the general format is:
my_function(a = 1, b =5)
where my_function is the name of the function, a and b are arguments for which you provide values. So in the vignette code, regions, bam_files and assay are arguments to the function metagene2$new.
Now, metagene2 uses the R6 system, that means when you load the package with library(metagene2), it creates an object called metagene2. This object contains a number of functions and variables, that you can access with $.
So, metagene2$new() calls the function new() defined within the metagene2 object, which creates a new object of class metagene2, which you can save in a variable called mg. But you can choose a different name for that variable, so you could call: