There is a fantastic Tidy Tuesday blog post by Julia Silge in October of 2022 called " Find high FREX and high lift words for TidyTuesday Stranger Things dialogue". The code is all there, and in a video Julia walks through creating and using the script. All excellent. My problem is that when I copy and run the code in Rstudio I get an error about using "frex" with matrix =. I can't seem to track down a solution. Here is all the code, up to and including where the error occurs.
Does anyone have an idea of why this works in the video but not when I try to run in Rstudio? Appreciate any help becuase this looks like a great addition to text mining. Thanks Julia, and thanks for any suggestions.
library(tidyverse)
episodes_raw <- read_csv('https://raw.githubusercontent.com/rfordatascience/tidytuesday/master/data/2022/2022-10-18/stranger_things_all_dialogue.csv')
#> Rows: 32519 Columns: 8
#> ── Column specification ────────────────────────────────────────────────────────
#> Delimiter: ","
#> chr (3): raw_text, stage_direction, dialogue
#> dbl (3): season, episode, line
#> time (2): start_time, end_time
#>
#> ℹ Use `spec()` to retrieve the full column specification for this data.
#> ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
dialogue <-
episodes_raw %>%
filter(!is.na(dialogue)) %>%
mutate(season = paste0("season", season))
dialogue
#> # A tibble: 26,041 × 8
#> season episode line raw_text stage…¹ dialo…² start…³ end_t…⁴
#> <chr> <dbl> <dbl> <chr> <chr> <chr> <time> <time>
#> 1 season1 1 9 [Mike] Something is co… [Mike] Someth… 01'44" 01'48"
#> 2 season1 1 10 A shadow grows on the … <NA> A shad… 01'48" 01'52"
#> 3 season1 1 11 -It is almost here. -W… <NA> It is … 01'52" 01'54"
#> 4 season1 1 12 What if it's the Demog… <NA> What i… 01'54" 01'56"
#> 5 season1 1 13 Oh, Jesus, we're so sc… <NA> Oh, Je… 01'56" 01'59"
#> 6 season1 1 14 It's not the Demogorgo… <NA> It's n… 01'59" 02'00"
#> 7 season1 1 15 An army of troglodytes… <NA> An arm… 02'00" 02'02"
#> 8 season1 1 16 -Troglodytes? -Told ya… [chuck… Troglo… 02'02" 02'05"
#> 9 season1 1 18 [softly] Wait a minute. [softl… Wait a… 02'08" 02'09"
#> 10 season1 1 19 Did you hear that? <NA> Did yo… 02'10" 02'12"
#> # … with 26,031 more rows, and abbreviated variable names ¹stage_direction,
#> # ²dialogue, ³start_time, ⁴end_time
#____
library(tidytext)
tidy_dialogue <-
dialogue %>%
unnest_tokens(word, dialogue)
tidy_dialogue
#> # A tibble: 143,885 × 8
#> season episode line raw_text stage…¹ start…² end_t…³ word
#> <chr> <dbl> <dbl> <chr> <chr> <time> <time> <chr>
#> 1 season1 1 9 [Mike] Something is comi… [Mike] 01'44" 01'48" some…
#> 2 season1 1 9 [Mike] Something is comi… [Mike] 01'44" 01'48" is
#> 3 season1 1 9 [Mike] Something is comi… [Mike] 01'44" 01'48" comi…
#> 4 season1 1 9 [Mike] Something is comi… [Mike] 01'44" 01'48" some…
#> 5 season1 1 9 [Mike] Something is comi… [Mike] 01'44" 01'48" hung…
#> 6 season1 1 9 [Mike] Something is comi… [Mike] 01'44" 01'48" for
#> 7 season1 1 9 [Mike] Something is comi… [Mike] 01'44" 01'48" blood
#> 8 season1 1 10 A shadow grows on the wa… <NA> 01'48" 01'52" a
#> 9 season1 1 10 A shadow grows on the wa… <NA> 01'48" 01'52" shad…
#> 10 season1 1 10 A shadow grows on the wa… <NA> 01'48" 01'52" grows
#> # … with 143,875 more rows, and abbreviated variable names ¹stage_direction,
#> # ²start_time, ³end_time
#______
library(tidylo)
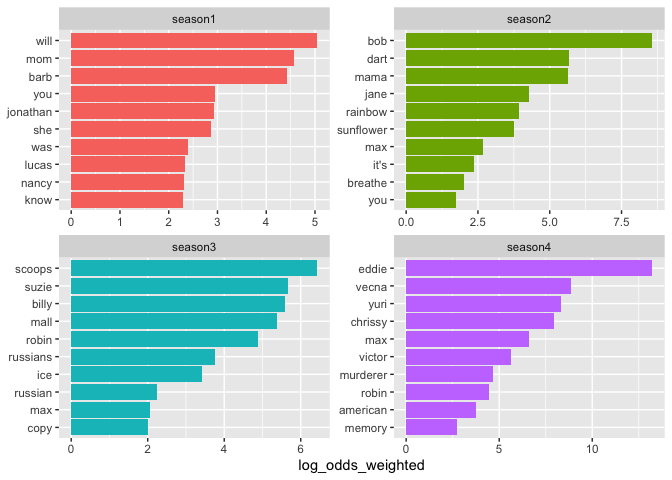
tidy_dialogue %>%
count(season, word, sort = TRUE) %>%
bind_log_odds(season, word, n) %>%
filter(n > 20) %>%
group_by(season) %>%
slice_max(log_odds_weighted, n = 10) %>%
mutate(word = reorder_within(word, log_odds_weighted, season)) %>%
ggplot(aes(log_odds_weighted, word, fill = season)) +
geom_col(show.legend = FALSE) +
facet_wrap(vars(season), scales = "free") +
scale_y_reordered() +
labs(y = NULL)
#______
dialogue_sparse <-
tidy_dialogue %>%
mutate(document = paste(season, episode, sep = "_")) %>%
count(document, word) %>%
filter(n > 5) %>%
cast_sparse(document, word, n)
dim(dialogue_sparse)
#> [1] 34 562
#_________
library(stm)
#> stm v1.3.6 successfully loaded. See ?stm for help.
#> Papers, resources, and other materials at structuraltopicmodel.com
set.seed(123)
topic_model <- stm(dialogue_sparse, K = 5, verbose = FALSE)
summary(topic_model)
#> A topic model with 5 topics, 34 documents and a 562 word dictionary.
#> Topic 1 Top Words:
#> Highest Prob: you, i, the, to, a, and, it
#> FREX: max, mean, they're, i'm, don't, i, know
#> Lift: dart, clarke, mr, soon, better, duck, mistakes
#> Score: girlfriend, max, dart, duck, mr, building, kline's
#> Topic 2 Top Words:
#> Highest Prob: you, i, the, a, to, it, and
#> FREX: he's, let, we, he, go, us, what
#> Lift: flayer, party, fact, flayed, children, hold, tied
#> Score: flayer, ice, cherry, says, bob, key, code
#> Topic 3 Top Words:
#> Highest Prob: you, i, the, to, a, and, that
#> FREX: eddie, as, only, chrissy, make, has, much
#> Lift: ray, being, boobies, california, dad, deal, death
#> Score: ray, eddie, only, chrissy, try, had, vecna
#> Topic 4 Top Words:
#> Highest Prob: you, i, the, to, it, a, and
#> FREX: go, mike, come, jonathan, on, okay, get
#> Lift: jonathan, gone, jingle, kids, terry, answer, blood
#> Score: christmas, jonathan, copy, jingle, gone, bell, scoops
#> Topic 5 Top Words:
#> Highest Prob: you, i, the, to, a, what, it
#> FREX: will, mom, lucas, murderer, barb, he, know
#> Lift: demogorgon, shut, chug, missing, weird, probably, threeonefive
#> Score: threeonefive, mom, barb, lucas, murderer, hopper, sunflower
#_______
tidy(topic_model, matrix = "beta") %>%
group_by(topic) %>%
slice_max(beta, n = 10, ) %>%
mutate(rank = row_number()) %>%
ungroup() %>%
select(-beta) %>%
pivot_wider(
names_from = "topic",
names_glue = "topic {.name}",
values_from = term
) %>%
select(-rank) %>%
knitr::kable()
| topic 1 | topic 2 | topic 3 | topic 4 | topic 5 |
|---|---|---|---|---|
| you | you | you | you | you |
| i | i | i | i | i |
| the | the | the | the | the |
| to | a | to | to | to |
| a | to | a | it | a |
| and | it | and | a | what |
| it | and | that | and | it |
| that | what | it | is | and |
| what | that | is | go | that |
| it’s | we | we | this | is |
#_________
tidy(topic_model, matrix = "frex") %>%
group_by(topic) %>%
slice_max(beta, n = 10, ) %>%
mutate(rank = row_number()) %>%
ungroup() %>%
select(-beta) %>%
pivot_wider(
names_from = "topic",
names_glue = "topic {.name}",
values_from = term
) %>%
select(-rank) %>%
knitr::kable()
#> Error in match.arg(matrix): 'arg' should be one of "beta", "gamma", "theta"
Created on 2022-12-18 with reprex v2.0.2