Hello,
I have a data cleaning task that is unexpectedly throwing me a curveball. I created a small sample set to validate and test against.
The core of the computation I'm trying to accomplish is to create a new column which contains the count of previous stage (grouped by the metadata). The formula for this is count_at_stage_zero - sum (counts for 0 < stage < current stage).
- Stages: 0 is initial so count here is the number of things that began at Stage 0. All other stages the count is really a measure of failure. I view it as "this many things went wrong".
This looks like the following table created in Excel. Count_Prev_Stage is my new column and everything else is my input data.
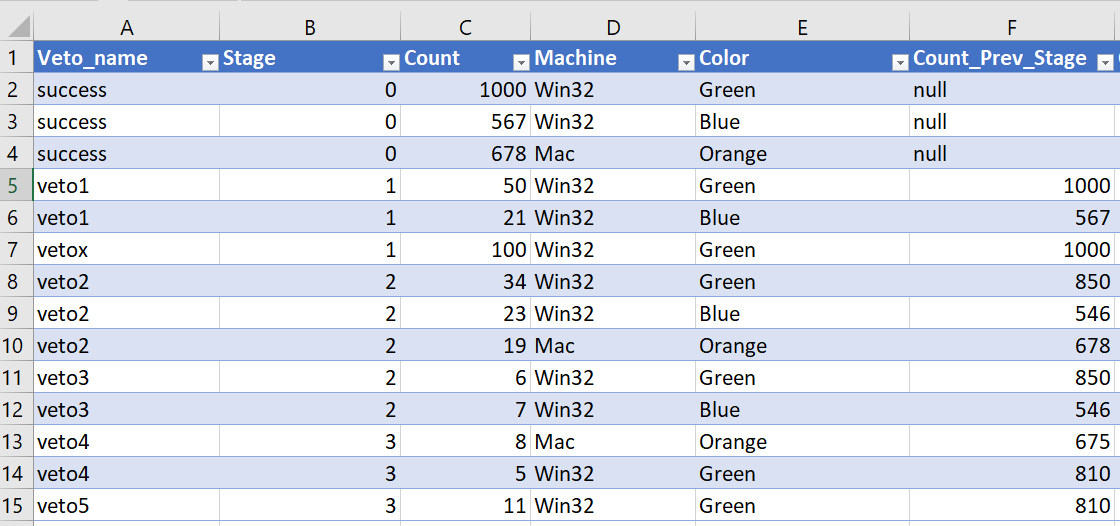
I don't have code to share since I'm at the "stumped" phase of the process. Any help or direction on how to calculate Count_Prev_Stage would be super appreciated. If there is something I can do to clarify the problem so that help is easier to give please let me know. I'm not sure I've eloquently translated what is in my head to a scoped problem.
Thank you,
Kathleen