I am in need in help due to I have been unable to resolve this problem.
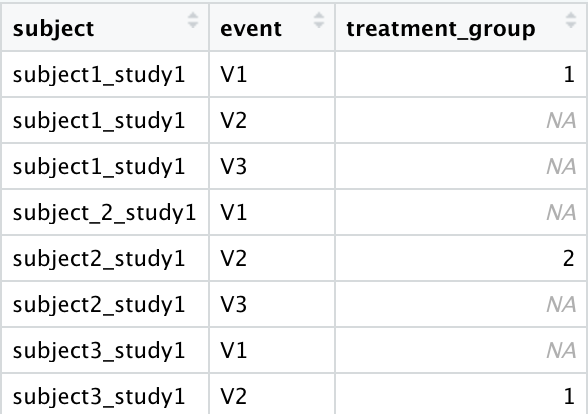
I am working in a clinical database when several subjects were longitudinal observed and so I have various observations for the same ID. The patients were randomized to one of two treatments groups (1 or 2 within the data) but the data only registered the group in one of the four possible observations. What I want is to replicate the treatment group assigned in each of the observations based of one of the IDs that have one (each unique ID and each observation with their assigned group).
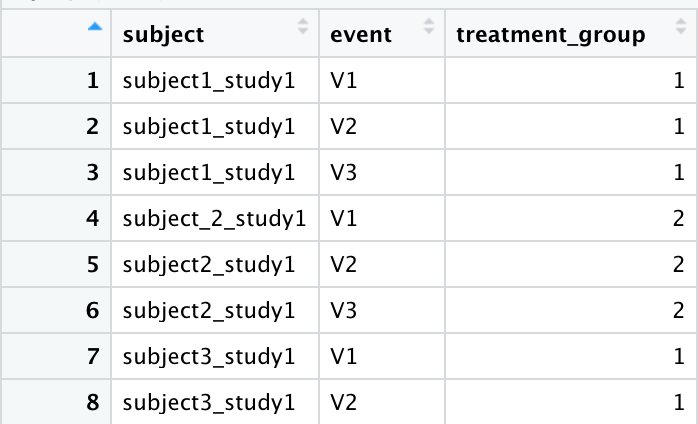
I am not entirely sure what you want to achieve. Below is my guess, but please feel free to provide additional information as to what you are expecting the end-result to look like.
(Note that I split the subject variable into a subject and a study variable.)
This simply fills the values missing for the treatment_group variable with the preceding value. Might not be what you are after; if not, please provide some further context so that we can help you out.
Thanks!
I am sorry for the misunderstanding. I am trying to fill the treatment_group column so that it may have their value according to each unique ID.
So that this: