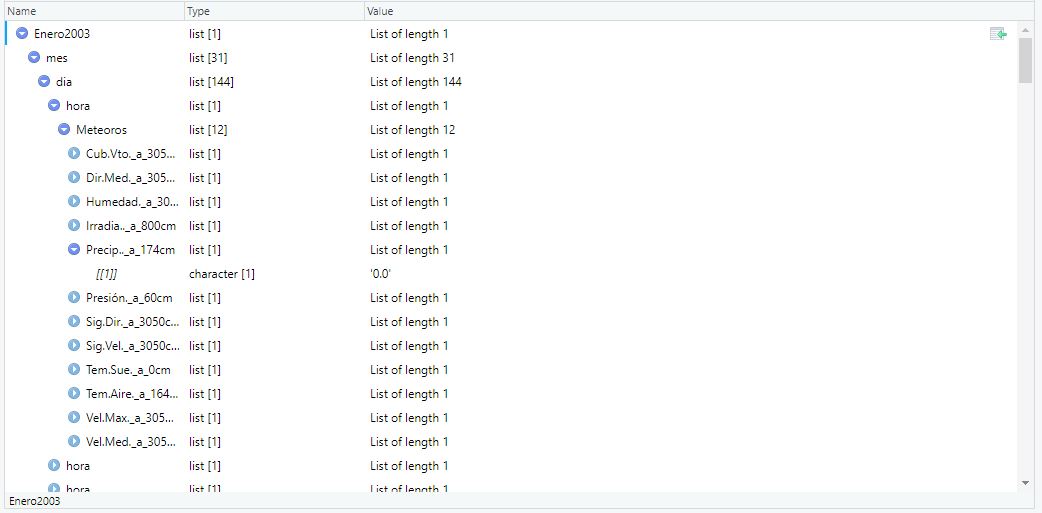
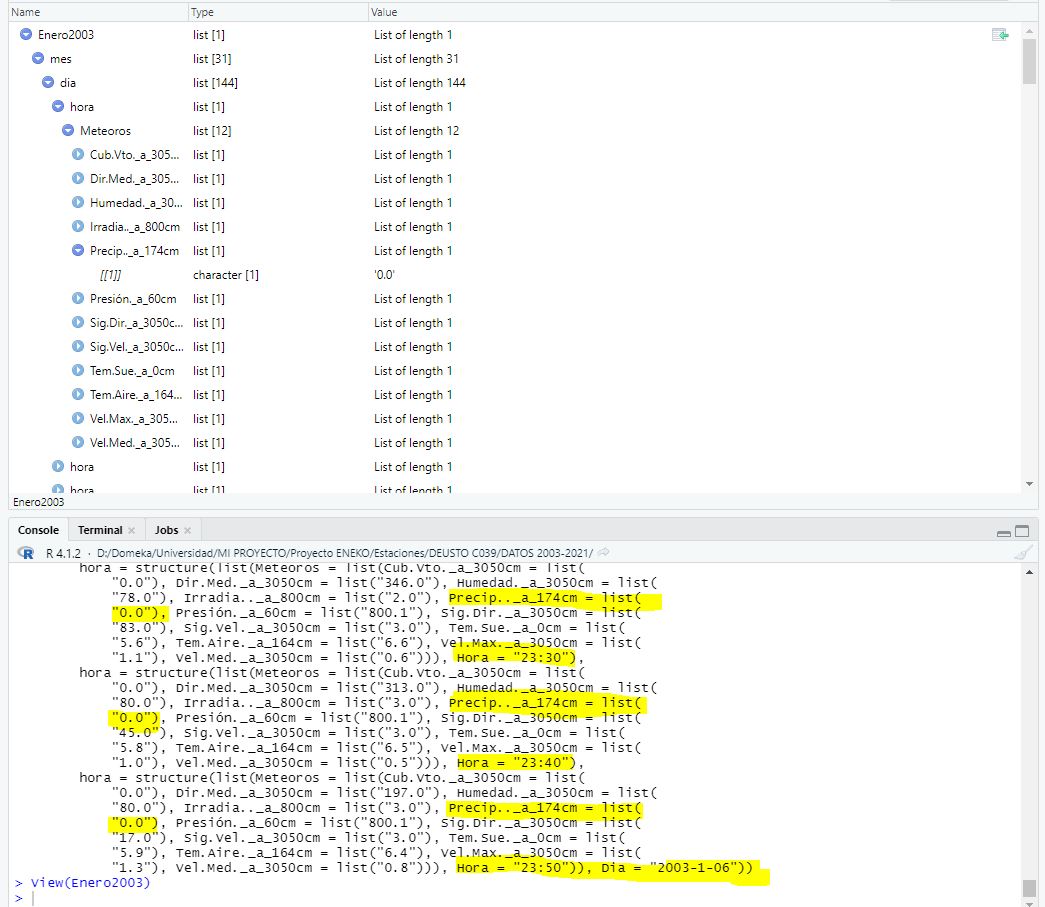
But I guess I'm doing something wrong. I need the information of the "Precip". The file is basically all the days of the month divided in every 10 minutes.
I should have uploaded the whole file, because as you said this is just a screenshot and it might not be clear. What I am attempting to do, is organize the data into a data frame, but I do not know how to properly adjust my code to obtain that.
is what size? It may not be possible to post it all, and shouldn’t be necessary, since we only need to figure out how to extract to the level of the one variable.
The main root is "mes"
After there is "dia" which is 31 times as it's each day of the month.
Then it's "hora" and "meteoros" which is the time of the day every 10 minutes, so every day it appears 144 times.
I hope this makes sense, if not I'll provide you any information you need.
I recommend switch from trying to use XML library to xml2
use xml2's read_xml and then its as_list, then other toolsets can be used such as purrr 's map family of functions.
I think in your precise case, probably when you turn it to a list, it will be a list of Dia entries. you could maybe therefore head() your list, to maybe something like 10 entries and use dput() to share that to the forum, if you want help exracting the Precip etc.