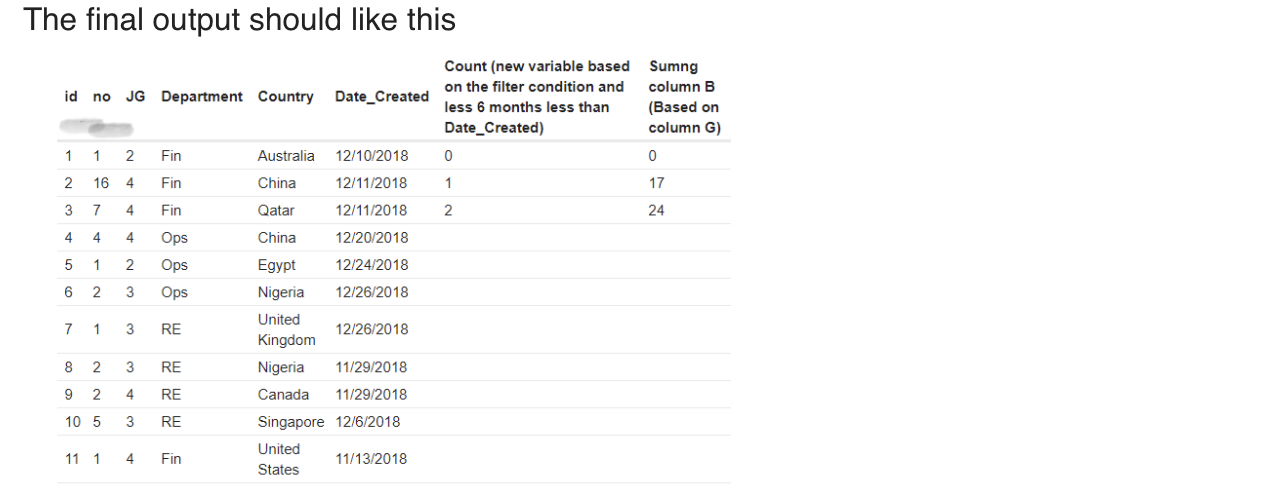
Please find the dataset which i am trying to execute.
structure(list(Id = 1:293, nos = c(4L, 2L, 3L, 4L, 5L, 19L, 7L,
1L, 2L, 1L, 9L, 2L, 2L, 3L, 2L, 1L, 2L, 1L, 6L, 1L, 3L, 17L,
16L, 12L, 7L, 4L, 3L, 2L, 2L, 1L, 3L, 3L, 12L, 5L, 4L, 7L, 3L,
9L, 10L, 11L, 4L, 13L, 12L, 17L, 1L, 3L, 2L, 1L, 5L, 4L, 1L,
8L, 1L, 1L, 1L, 16L, 7L, 4L, 1L, 2L, 1L, 2L, 2L, 5L, 1L, 1L,
8L, 1L, 1L, 9L, 2L, 9L, 2L, 1L, 2L, 1L, 2L, 1L, 2L, 4L, 1L, 1L,
1L, 4L, 3L, 2L, 9L, 1L, 1L, 1L, 4L, 4L, 7L, 3L, 5L, 5L, 4L, 9L,
3L, 1L, 6L, 1L, 7L, 3L, 10L, 19L, 1L, 2L, 3L, 1L, 7L, 3L, 5L,
5L, 7L, 4L, 10L, 4L, 1L, 1L, 3L, 5L, 4L, 5L, 4L, 8L, 2L, 5L,
9L, 6L, 5L, 4L, 8L, 6L, 4L, 9L, 5L, 5L, 6L, 9L, 8L, 6L, 4L, 1L,
7L, 7L, 8L, 2L, 9L, 4L, 9L, 7L, 7L, 4L, 8L, 2L, 1L, 6L, 2L, 8L,
1L, 4L, 1L, 4L, 1L, 1L, 4L, 6L, 1L, 5L, 1L, 4L, 2L, 1L, 7L, 1L,
3L, 7L, 6L, 3L, 7L, 3L, 1L, 6L, 8L, 14L, 17L, 5L, 15L, 4L, 4L,
9L, 1L, 1L, 5L, 3L, 2L, 3L, 9L, 1L, 2L, 2L, 1L, 4L, 3L, 2L, 5L,
4L, 1L, 1L, 4L, 6L, 1L, 2L, 5L, 5L, 2L, 6L, 4L, 7L, 6L, 7L, 7L,
1L, 3L, 1L, 1L, 6L, 3L, 5L, 8L, 1L, 5L, 3L, 3L, 2L, 1L, 3L, 1L,
1L, 2L, 1L, 5L, 2L, 2L, 2L, 6L, 3L, 3L, 2L, 2L, 1L, 3L, 1L, 2L,
6L, 1L, 1L, 3L, 4L, 2L, 13L, 5L, 3L, 6L, 1L, 3L, 2L, 3L, 1L,
5L, 2L, 2L, 2L, 3L, 1L, 3L, 4L, 1L, 1L, 1L, 3L, 2L, 5L, 2L, 2L,
4L, 2L, 1L, 9L, 2L, 1L, 2L), location = structure(c(10L, 10L,
10L, 18L, 18L, 18L, 2L, 2L, 10L, 11L, 18L, 17L, 17L, 17L, 17L,
17L, 17L, 3L, 3L, 3L, 3L, 4L, 4L, 4L, 8L, 17L, 10L, 10L, 10L,
8L, 10L, 9L, 9L, 9L, 9L, 9L, 9L, 9L, 9L, 9L, 18L, 9L, 18L, 13L,
10L, 18L, 12L, 18L, 10L, 15L, 16L, 9L, 5L, 5L, 2L, 5L, 15L, 5L,
6L, 11L, 17L, 11L, 4L, 16L, 18L, 18L, 18L, 8L, 17L, 18L, 18L,
8L, 10L, 10L, 10L, 10L, 2L, 2L, 2L, 2L, 17L, 17L, 18L, 11L, 11L,
11L, 4L, 1L, 1L, 11L, 12L, 12L, 12L, 12L, 12L, 12L, 12L, 12L,
12L, 10L, 9L, 10L, 9L, 2L, 15L, 18L, 11L, 10L, 9L, 8L, 4L, 4L,
4L, 18L, 18L, 18L, 18L, 18L, 8L, 8L, 8L, 18L, 10L, 10L, 18L,
18L, 17L, 10L, 8L, 8L, 10L, 8L, 18L, 18L, 18L, 18L, 18L, 18L,
10L, 17L, 8L, 8L, 8L, 8L, 18L, 18L, 18L, 10L, 18L, 10L, 18L,
18L, 18L, 17L, 17L, 17L, 17L, 17L, 17L, 17L, 17L, 17L, 17L, 10L,
9L, 2L, 16L, 16L, 18L, 18L, 16L, 11L, 10L, 18L, 2L, 7L, 2L, 8L,
8L, 10L, 8L, 8L, 18L, 18L, 8L, 8L, 8L, 8L, 9L, 18L, 18L, 18L,
8L, 8L, 18L, 18L, 2L, 3L, 4L, 10L, 14L, 8L, 18L, 9L, 18L, 18L,
18L, 8L, 9L, 17L, 4L, 11L, 9L, 11L, 11L, 8L, 18L, 18L, 4L, 4L,
4L, 4L, 4L, 18L, 18L, 18L, 10L, 2L, 2L, 2L, 2L, 16L, 18L, 10L,
10L, 16L, 18L, 9L, 8L, 10L, 16L, 12L, 12L, 12L, 12L, 12L, 12L,
12L, 12L, 12L, 12L, 12L, 12L, 12L, 12L, 12L, 12L, 10L, 18L, 18L,
18L, 9L, 9L, 18L, 9L, 18L, 18L, 5L, 18L, 10L, 2L, 10L, 2L, 5L,
2L, 18L, 8L, 18L, 17L, 10L, 17L, 11L, 10L, 9L, 11L, 18L, 17L,
17L, 17L, 11L, 10L, 11L, 8L), .Label = c("Argentina", "Australia",
"Brazil", "Canada", "China", "Egypt", "Germany", "India", "Malaysia",
"Netherlands", "Nigeria", "Norway", "Oman", "Philippines", "Qatar",
"Singapore", "United Kingdom", "United States"), class = "factor"),
grade = c(3L, 3L, 3L, 4L, 4L, 4L, 3L, 4L, 3L, 2L, 4L, 2L,
2L, 2L, 2L, 2L, 2L, 4L, 4L, 4L, 3L, 4L, 4L, 3L, 4L, 2L, 3L,
2L, 2L, 3L, 4L, 2L, 3L, 3L, 3L, 3L, 3L, 4L, 4L, 4L, 2L, 3L,
3L, 4L, 4L, 4L, 2L, 4L, 3L, 4L, 4L, 2L, 3L, 3L, 2L, 4L, 4L,
4L, 2L, 3L, 3L, 3L, 4L, 3L, 4L, 2L, 3L, 4L, 4L, 2L, 4L, 3L,
3L, 4L, 3L, 3L, 4L, 4L, 4L, 3L, 4L, 3L, 2L, 3L, 3L, 3L, 4L,
4L, 4L, 3L, 3L, 3L, 3L, 3L, 3L, 4L, 4L, 4L, 4L, 4L, 2L, 3L,
4L, 3L, 4L, 3L, 2L, 4L, 4L, 4L, 4L, 3L, 3L, 3L, 4L, 4L, 3L,
3L, 2L, 4L, 4L, 2L, 2L, 2L, 3L, 4L, 2L, 2L, 2L, 2L, 2L, 4L,
2L, 2L, 3L, 3L, 2L, 2L, 2L, 2L, 4L, 2L, 3L, 3L, 4L, 3L, 3L,
2L, 3L, 3L, 4L, 4L, 4L, 2L, 3L, 2L, 2L, 3L, 2L, 3L, 3L, 3L,
4L, 3L, 3L, 3L, 4L, 3L, 4L, 4L, 4L, 4L, 4L, 2L, 4L, 3L, 4L,
4L, 4L, 2L, 4L, 3L, 3L, 4L, 4L, 4L, 4L, 4L, 3L, 3L, 3L, 3L,
3L, 3L, 4L, 4L, 4L, 3L, 4L, 4L, 4L, 4L, 3L, 4L, 4L, 4L, 3L,
4L, 3L, 3L, 3L, 4L, 4L, 4L, 4L, 4L, 3L, 4L, 4L, 4L, 4L, 3L,
4L, 4L, 3L, 4L, 4L, 2L, 3L, 3L, 4L, 4L, 3L, 2L, 4L, 4L, 4L,
3L, 3L, 3L, 4L, 3L, 4L, 2L, 3L, 4L, 3L, 4L, 4L, 4L, 2L, 3L,
3L, 3L, 4L, 3L, 4L, 3L, 3L, 4L, 4L, 4L, 4L, 3L, 4L, 4L, 3L,
4L, 4L, 3L, 2L, 3L, 3L, 3L, 4L, 3L, 4L, 2L, 4L, 4L, 4L, 4L,
4L, 4L, 3L, 2L, 3L, 4L, 4L, 3L, 4L, 4L, 4L), Date_Created = structure(c(66L,
67L, 71L, 74L, 74L, 78L, 90L, 96L, 97L, 103L, 104L, 109L,
109L, 109L, 109L, 109L, 109L, 111L, 111L, 111L, 111L, 114L,
114L, 114L, 116L, 116L, 121L, 121L, 121L, 130L, 134L, 125L,
126L, 126L, 126L, 126L, 126L, 126L, 126L, 126L, 128L, 132L,
29L, 14L, 14L, 16L, 20L, 25L, 26L, 44L, 36L, 36L, 37L, 38L,
50L, 9L, 2L, 5L, 6L, 64L, 56L, 58L, 60L, 70L, 76L, 77L, 68L,
72L, 75L, 85L, 86L, 79L, 80L, 80L, 80L, 80L, 80L, 80L, 80L,
81L, 87L, 87L, 100L, 89L, 94L, 94L, 102L, 106L, 119L, 108L,
112L, 112L, 112L, 112L, 112L, 112L, 112L, 112L, 112L, 115L,
122L, 133L, 123L, 124L, 127L, 136L, 142L, 139L, 140L, 28L,
12L, 12L, 12L, 12L, 12L, 12L, 12L, 12L, 12L, 12L, 12L, 12L,
12L, 12L, 12L, 12L, 12L, 12L, 12L, 12L, 12L, 12L, 12L, 12L,
12L, 12L, 12L, 12L, 12L, 12L, 12L, 12L, 12L, 12L, 12L, 12L,
12L, 12L, 12L, 12L, 12L, 12L, 12L, 12L, 12L, 12L, 12L, 12L,
12L, 12L, 12L, 12L, 12L, 13L, 17L, 18L, 18L, 18L, 18L, 18L,
18L, 27L, 34L, 34L, 40L, 48L, 51L, 52L, 52L, 52L, 52L, 52L,
52L, 52L, 52L, 52L, 52L, 52L, 10L, 10L, 10L, 1L, 3L, 3L,
4L, 7L, 8L, 63L, 65L, 54L, 55L, 57L, 59L, 61L, 61L, 62L,
69L, 73L, 84L, 82L, 82L, 83L, 101L, 101L, 101L, 88L, 91L,
92L, 93L, 93L, 93L, 93L, 93L, 95L, 95L, 98L, 99L, 107L, 107L,
107L, 107L, 117L, 118L, 118L, 105L, 110L, 113L, 120L, 135L,
135L, 129L, 131L, 131L, 131L, 131L, 131L, 131L, 131L, 131L,
131L, 131L, 131L, 131L, 131L, 131L, 131L, 131L, 141L, 141L,
137L, 138L, 24L, 24L, 24L, 30L, 31L, 31L, 32L, 11L, 15L,
19L, 19L, 21L, 21L, 21L, 22L, 23L, 42L, 42L, 43L, 45L, 46L,
46L, 33L, 35L, 39L, 41L, 41L, 41L, 47L, 49L, 49L, 53L), .Label = c("1/10/2018",
"1/12/2017", "1/12/2018", "1/15/2018", "1/20/2017", "1/25/2017",
"1/25/2018", "1/29/2018", "1/6/2017", "1/8/2018", "10/10/2018",
"10/11/2017", "10/12/2017", "10/14/2016", "10/15/2018", "10/17/2016",
"10/17/2017", "10/20/2017", "10/22/2018", "10/23/2016", "10/23/2018",
"10/24/2018", "10/25/2018", "10/3/2018", "10/30/2016", "10/31/2016",
"10/31/2017", "10/4/2017", "10/5/2016", "10/5/2018", "10/8/2018",
"10/9/2018", "11/13/2018", "11/15/2017", "11/15/2018", "11/18/2016",
"11/24/2016", "11/25/2016", "11/26/2018", "11/29/2017", "11/29/2018",
"11/5/2018", "11/6/2018", "11/7/2016", "11/7/2018", "11/8/2018",
"12/10/2018", "12/11/2017", "12/11/2018", "12/13/2016", "12/18/2017",
"12/22/2017", "12/26/2018", "2/12/2018", "2/14/2018", "2/16/2017",
"2/16/2018", "2/17/2017", "2/21/2018", "2/23/2017", "2/26/2018",
"2/27/2018", "2/6/2018", "2/8/2017", "2/8/2018", "3/1/2016",
"3/15/2016", "3/15/2017", "3/19/2018", "3/2/2017", "3/21/2016",
"3/21/2017", "3/28/2018", "3/31/2016", "3/31/2017", "3/6/2017",
"3/8/2017", "4/1/2016", "4/11/2017", "4/13/2017", "4/14/2017",
"4/25/2018", "4/30/2018", "4/4/2018", "4/5/2017", "4/7/2017",
"5/1/2017", "5/11/2018", "5/12/2017", "5/13/2016", "5/14/2018",
"5/15/2018", "5/16/2018", "5/17/2017", "5/21/2018", "5/24/2016",
"5/25/2016", "5/25/2018", "5/29/2018", "5/3/2017", "5/3/2018",
"5/31/2017", "6/1/2016", "6/13/2016", "6/13/2018", "6/2/2017",
"6/2/2018", "6/20/2017", "6/22/2016", "6/22/2018", "6/26/2016",
"6/26/2017", "6/26/2018", "6/28/2016", "6/29/2017", "6/30/2016",
"6/4/2018", "6/5/2018", "6/6/2017", "7/10/2018", "7/29/2016",
"7/7/2017", "8/10/2017", "8/11/2017", "8/12/2016", "8/16/2016",
"8/16/2017", "8/17/2016", "8/17/2018", "8/2/2016", "8/21/2018",
"8/25/2016", "8/3/2017", "8/4/2016", "8/6/2018", "9/1/2017",
"9/18/2018", "9/20/2018", "9/21/2017", "9/27/2017", "9/4/2018",
"9/5/2017"), class = "factor"), less6month = structure(c(130L,
131L, 135L, 138L, 138L, 4L, 16L, 22L, 23L, 29L, 30L, 35L,
35L, 35L, 35L, 35L, 35L, 37L, 37L, 37L, 37L, 40L, 40L, 40L,
42L, 42L, 2L, 2L, 2L, 53L, 57L, 48L, 49L, 49L, 49L, 49L,
49L, 49L, 49L, 49L, 51L, 55L, 83L, 69L, 69L, 71L, 75L, 80L,
80L, 98L, 90L, 90L, 91L, 92L, 104L, 116L, 109L, 112L, 113L,
128L, 120L, 122L, 124L, 134L, 140L, 141L, 132L, 136L, 139L,
11L, 12L, 5L, 6L, 6L, 6L, 6L, 6L, 6L, 6L, 7L, 13L, 13L, 26L,
15L, 20L, 20L, 28L, 32L, 45L, 34L, 38L, 38L, 38L, 38L, 38L,
38L, 38L, 38L, 38L, 41L, 3L, 56L, 46L, 47L, 50L, 59L, 65L,
62L, 63L, 82L, 67L, 67L, 67L, 67L, 67L, 67L, 67L, 67L, 67L,
67L, 67L, 67L, 67L, 67L, 67L, 67L, 67L, 67L, 67L, 67L, 67L,
67L, 67L, 67L, 67L, 67L, 67L, 67L, 67L, 67L, 67L, 67L, 67L,
67L, 67L, 67L, 67L, 67L, 67L, 67L, 67L, 67L, 67L, 67L, 67L,
67L, 67L, 67L, 67L, 67L, 67L, 67L, 67L, 68L, 72L, 73L, 73L,
73L, 73L, 73L, 73L, 81L, 88L, 88L, 94L, 102L, 105L, 106L,
106L, 106L, 106L, 106L, 106L, 106L, 106L, 106L, 106L, 106L,
117L, 117L, 117L, 108L, 110L, 110L, 111L, 114L, 115L, 127L,
129L, 118L, 119L, 121L, 123L, 125L, 125L, 126L, 133L, 137L,
10L, 8L, 8L, 9L, 27L, 27L, 27L, 14L, 17L, 18L, 19L, 19L,
19L, 19L, 19L, 21L, 21L, 24L, 25L, 33L, 33L, 33L, 33L, 43L,
44L, 44L, 31L, 36L, 39L, 1L, 58L, 58L, 52L, 54L, 54L, 54L,
54L, 54L, 54L, 54L, 54L, 54L, 54L, 54L, 54L, 54L, 54L, 54L,
54L, 64L, 64L, 60L, 61L, 79L, 79L, 79L, 84L, 85L, 85L, 86L,
66L, 70L, 74L, 74L, 76L, 76L, 76L, 77L, 78L, 96L, 96L, 97L,
99L, 100L, 100L, 87L, 89L, 93L, 95L, 95L, 95L, 101L, 103L,
103L, 107L), .Label = c("1/10/2018", "1/29/2016", "1/7/2017",
"10/1/2015", "10/11/2016", "10/13/2016", "10/14/2016", "10/25/2017",
"10/30/2017", "10/4/2017", "10/5/2016", "10/7/2016", "11/1/2016",
"11/11/2017", "11/12/2016", "11/13/2015", "11/14/2017", "11/15/2017",
"11/16/2017", "11/17/2016", "11/21/2017", "11/24/2015", "11/25/2015",
"11/25/2017", "11/29/2017", "11/3/2016", "11/3/2017", "11/30/2016",
"12/1/2015", "12/13/2015", "12/13/2017", "12/2/2016", "12/2/2017",
"12/20/2016", "12/22/2015", "12/22/2017", "12/26/2015", "12/26/2016",
"12/26/2017", "12/28/2015", "12/29/2016", "12/30/2015", "12/4/2017",
"12/5/2017", "12/6/2016", "2/10/2017", "2/11/2017", "2/12/2016",
"2/16/2016", "2/16/2017", "2/17/2016", "2/17/2018", "2/2/2016",
"2/21/2018", "2/25/2016", "2/3/2017", "2/4/2016", "2/6/2018",
"3/1/2017", "3/18/2018", "3/20/2018", "3/21/2017", "3/27/2017",
"3/4/2018", "3/5/2017", "4/10/2018", "4/11/2017", "4/12/2017",
"4/14/2016", "4/15/2018", "4/17/2016", "4/17/2017", "4/20/2017",
"4/22/2018", "4/23/2016", "4/23/2018", "4/24/2018", "4/25/2018",
"4/3/2018", "4/30/2016", "4/30/2017", "4/4/2017", "4/5/2016",
"4/5/2018", "4/8/2018", "4/9/2018", "5/13/2018", "5/15/2017",
"5/15/2018", "5/18/2016", "5/24/2016", "5/25/2016", "5/26/2018",
"5/29/2017", "5/29/2018", "5/5/2018", "5/6/2018", "5/7/2016",
"5/7/2018", "5/8/2018", "6/10/2018", "6/11/2017", "6/11/2018",
"6/13/2016", "6/18/2017", "6/22/2017", "6/26/2018", "7/10/2017",
"7/12/2016", "7/12/2017", "7/15/2017", "7/20/2016", "7/25/2016",
"7/25/2017", "7/29/2017", "7/6/2016", "7/8/2017", "8/12/2017",
"8/14/2017", "8/16/2016", "8/16/2017", "8/17/2016", "8/21/2017",
"8/23/2016", "8/26/2017", "8/27/2017", "8/6/2017", "8/8/2016",
"8/8/2017", "9/1/2015", "9/15/2015", "9/15/2016", "9/19/2017",
"9/2/2016", "9/21/2015", "9/21/2016", "9/28/2017", "9/30/2015",
"9/30/2016", "9/6/2016", "9/8/2016"), class = "factor")), class = "data.frame", row.names = c(NA,
-293L))