Hello,
I have this problem with grouping in ggplot 2.
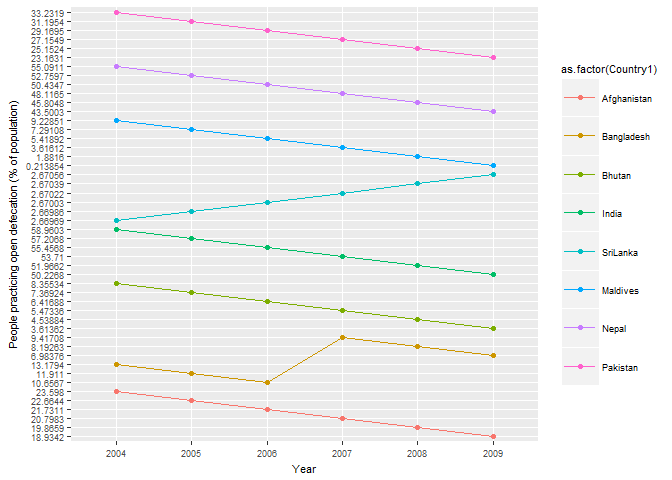
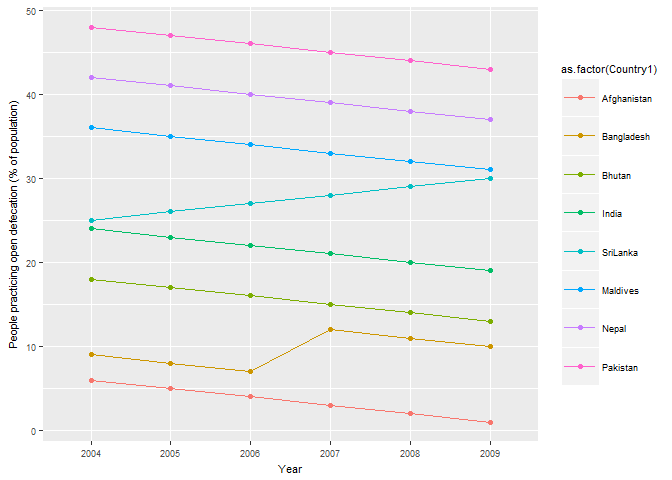
When I am grouping with countries then if as.numeric is not passed to the y axis aesthetics then I get a weird y axis. But when as.numeric is passed to the y axis aesthetics then the grouping is not as per the values.
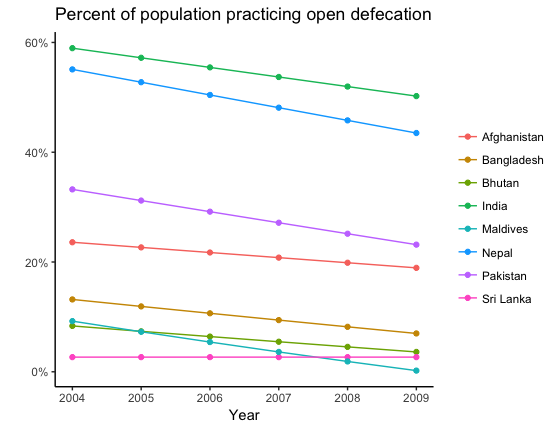
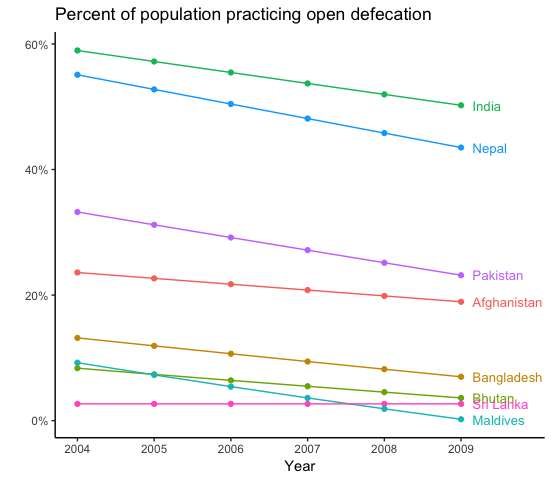
India is supposed to be at the top but it lies somewhere in the middle.
Any help is appreciated.
Data here:
https://drive.google.com/file/d/1sP8or8PKJ087rqLjzW2mgJuVfMXgjBV9/view?usp=sharing
library(readxl)
API_SH_STA_ODFC_ZS_DS2_en_excel_v2 <- read_excel("G:/replication/API_SH.STA.ODFC.ZS_DS2_en_excel_v2.xls")
world_bank1= API_SH_STA_ODFC_ZS_DS2_en_excel_v2
colnames(world_bank1)
#> [1] "Data Source" "World Development Indicators"
#> [3] "X__1" "X__2"
#> [5] "X__3" "X__4"
#> [7] "X__5" "X__6"
#> [9] "X__7" "X__8"
#> [11] "X__9" "X__10"
#> [13] "X__11" "X__12"
#> [15] "X__13" "X__14"
#> [17] "X__15" "X__16"
#> [19] "X__17" "X__18"
#> [21] "X__19" "X__20"
#> [23] "X__21" "X__22"
#> [25] "X__23" "X__24"
#> [27] "X__25" "X__26"
#> [29] "X__27" "X__28"
#> [31] "X__29" "X__30"
#> [33] "X__31" "X__32"
#> [35] "X__33" "X__34"
#> [37] "X__35" "X__36"
#> [39] "X__37" "X__38"
#> [41] "X__39" "X__40"
#> [43] "X__41" "X__42"
#> [45] "X__43" "X__44"
#> [47] "X__45" "X__46"
#> [49] "X__47" "X__48"
#> [51] "X__49" "X__50"
#> [53] "X__51" "X__52"
#> [55] "X__53" "X__54"
#> [57] "X__55" "X__56"
#> [59] "X__57" "X__58"
#> [61] "X__59" "X__60"
library(tidyverse)
world_bank2= world_bank1 %>%
select(1:3, 45:62)
world_bank3= world_bank2 %>%
filter(5, 22, 34, 111, 140, 154, 180, 186)
world_bank3= world_bank2[ c(5, 22, 34, 111, 140, 154, 180, 186), ]
colnames(world_bank3)
#> [1] "Data Source" "World Development Indicators"
#> [3] "X__1" "X__43"
#> [5] "X__44" "X__45"
#> [7] "X__46" "X__47"
#> [9] "X__48" "X__49"
#> [11] "X__50" "X__51"
#> [13] "X__52" "X__53"
#> [15] "X__54" "X__55"
#> [17] "X__56" "X__57"
#> [19] "X__58" "X__59"
#> [21] "X__60"
world_bank4= world_bank3 %>%
select(1:3,8:13)
colnames(world_bank4)= c("Data Source", "World Development Indicators", "Value", "2004", "2005", "2006",
"2007", "2008", "2009")
world_bank4$`Data Source`
#> [1] "Afghanistan" "Bangladesh" "Bhutan" "India" "Sri Lanka"
#> [6] "Maldives" "Nepal" "Pakistan"
world_bank5= t(world_bank4)
world_bank6= world_bank5[4:9, ]
world_bank6= as.data.frame(world_bank6)
colnames(world_bank6)= c("Afghanistan", "Bangladesh", "Bhutan" , "India" ,
"Sri Lanka", "Maldives", "Nepal", "Pakistan" )
world_bank6$Year= c("2004", "2005", "2006",
"2007", "2008", "2009")
world_bank7= as.data.frame(t(world_bank6))
Afghanistan=as.data.frame(t( world_bank7[1,]))
Bangladesh=as.data.frame(t( world_bank7[2,]))
Bhutan=as.data.frame(t( world_bank7[3,]))
India=as.data.frame(t( world_bank7[4,]))
SriLanka=as.data.frame(t( world_bank7[5,]))
Maldives=as.data.frame(t( world_bank7[6,]))
Nepal=as.data.frame(t( world_bank7[7,]))
Pakistan=as.data.frame(t( world_bank7[8,]))
colnames(Afghanistan)= "value1"
colnames(Bangladesh)= "value1"
colnames(Bhutan)= "value1"
colnames(India)= "value1"
colnames(SriLanka)= "value1"
colnames(Maldives)= "value1"
colnames(Nepal)= "value1"
colnames(Pakistan)= "value1"
Year1= c("2004", "2005", "2006",
"2007", "2008", "2009")
world_bank8= rbind(Afghanistan, Bangladesh, Bhutan, India, SriLanka, Maldives, Nepal, Pakistan)
world_bank8$Year= rep(Year1, 8)
Afghanistan1= as.data.frame(rep("Afghanistan", 6))
Bangladesh1= as.data.frame(rep("Bangladesh", 6))
Bhutan1= as.data.frame(rep("Bhutan", 6))
India1= as.data.frame(rep("India", 6))
SriLanka1= as.data.frame(rep("SriLanka", 6))
Maldives1= as.data.frame(rep("Maldives", 6))
Nepal1= as.data.frame(rep("Nepal", 6))
Pakistan1= as.data.frame(rep("Pakistan", 6))
colnames(Afghanistan1)= "value1"
colnames(Bangladesh1)= "value1"
colnames(Bhutan1)= "value1"
colnames(India1)= "value1"
colnames(SriLanka1)= "value1"
colnames(Maldives1)= "value1"
colnames(Nepal1)= "value1"
colnames(Pakistan1)= "value1"
Country= as.vector( rbind(Afghanistan1, Bangladesh1, Bhutan1, India1, SriLanka1, Maldives1, Nepal1, Pakistan1))
Country1= Country$value1
world_bank8= cbind(world_bank8, Country1)
colnames(world_bank8)= c("OpenDefacation", "Year", "Country1")
world_bank8= as.data.frame(world_bank8)
library(ggplot2)
graph1= ggplot(world_bank8, aes(x=Year, y=as.numeric(world_bank8$OpenDefacation), group= as.factor(world_bank8$Country1) ,
color= as.factor(Country1 )))+
geom_point()+ geom_line()+
theme(text = element_text(size=8), legend.key.size = unit(2,"line"), legend.key.width = unit(2, "line"))+
labs(y= "People practicing open defecation (% of population)")
graph1
graph2= ggplot(world_bank8, aes(x=Year, y=(world_bank8$OpenDefacation), group= as.factor(world_bank8$Country1) ,
color= as.factor(Country1 )))+
geom_point()+ geom_line()+
theme(text = element_text(size=8), legend.key.size = unit(2,"line"), legend.key.width = unit(2, "line"))+
labs(y= "People practicing open defecation (% of population)")
graph2
ggsave("Figure7.png", width = 12.8, height = 9.6, units = "cm", scale = 1, dpi = 300)
library(reprex)
install.packages("datapasta")
#> package 'datapasta' successfully unpacked and MD5 sums checked
#>
#> The downloaded binary packages are in
#> C:\Users\Tejendra\AppData\Local\Temp\Rtmp8ChdVQ\downloaded_packages
library(datapasta)
tribble_paste(world_bank8)
#> Warning in tribble_construct(input_table, oc = output_context): Column(s)
#> 1,3 have been converted from factor to character in tribble output.
#> tibble::tribble(
#> ~OpenDefacation, ~Year, ~Country1,
#> "23.598", "2004", "Afghanistan",
#> "22.6644", "2005", "Afghanistan",
#> "21.7311", "2006", "Afghanistan",
#> "20.7983", "2007", "Afghanistan",
#> "19.8659", "2008", "Afghanistan",
#> "18.9342", "2009", "Afghanistan",
#> "13.1794", "2004", "Bangladesh",
#> "11.911", "2005", "Bangladesh",
#> "10.6567", "2006", "Bangladesh",
#> "9.41708", "2007", "Bangladesh",
#> "8.19263", "2008", "Bangladesh",
#> "6.98376", "2009", "Bangladesh",
#> "8.35534", "2004", "Bhutan",
#> "7.36924", "2005", "Bhutan",
#> "6.41688", "2006", "Bhutan",
#> "5.47336", "2007", "Bhutan",
#> "4.53884", "2008", "Bhutan",
#> "3.61362", "2009", "Bhutan",
#> "58.9603", "2004", "India",
#> "57.2068", "2005", "India",
#> "55.4568", "2006", "India",
#> "53.71", "2007", "India",
#> "51.9662", "2008", "India",
#> "50.2268", "2009", "India",
#> "2.66969", "2004", "SriLanka",
#> "2.66986", "2005", "SriLanka",
#> "2.67003", "2006", "SriLanka",
#> "2.67022", "2007", "SriLanka",
#> "2.67039", "2008", "SriLanka",
#> "2.67056", "2009", "SriLanka",
#> "9.22851", "2004", "Maldives",
#> "7.29108", "2005", "Maldives",
#> "5.41892", "2006", "Maldives",
#> "3.61612", "2007", "Maldives",
#> "1.8816", "2008", "Maldives",
#> "0.213854", "2009", "Maldives",
#> "55.0911", "2004", "Nepal",
#> "52.7597", "2005", "Nepal",
#> "50.4347", "2006", "Nepal",
#> "48.1165", "2007", "Nepal",
#> "45.8048", "2008", "Nepal",
#> "43.5003", "2009", "Nepal",
#> "33.2319", "2004", "Pakistan",
#> "31.1954", "2005", "Pakistan",
#> "29.1695", "2006", "Pakistan",
#> "27.1549", "2007", "Pakistan",
#> "25.1524", "2008", "Pakistan",
#> "23.1631", "2009", "Pakistan"
#> )
Created on 2018-04-17 by the reprex package (v0.2.0).