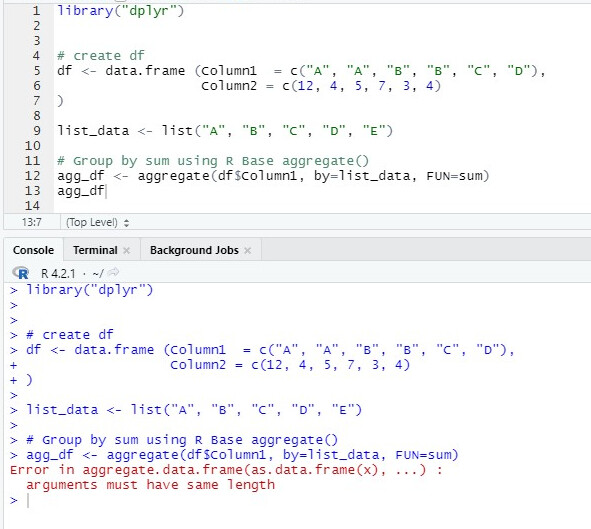
What does group_by() have to do with that? You don't do any grouped calculations whatsoever and the output seems rather random/arbitrary.
If you just want to add another row, you can use rbind() (or bind_rows() or rbindlist()). Otherwise, you should add a reprex or an actual example of relevant data (not just 4 rows with one entry "per group") as well as the logic behind your added row.
Then you could transform your column 1 into an actual factor but specify the levels that they contain "E". With tapply() you can then create the sum. Does this look like something you can use?
df <- data.frame(
col1 = c("A","A","B","B","C","D"),
col2 = c(12,4,5,7,3,4)
)
df$col1 <- factor(df$col1, levels = LETTERS[1:5], labels = LETTERS[1:5])
str(df$col1)
#> Factor w/ 5 levels "A","B","C","D",..: 1 1 2 2 3 4
tapply(df$col2, df$col1, sum)
#> A B C D E
#> 16 12 3 4 NA