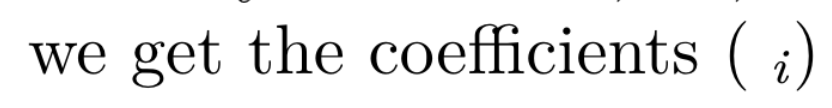I have a bookdown book with a lot of greek symbols inline. I've put them in using, I presume, Unicode. In RStudio the text looks like this example:
we get the coefficients (*β*~*i*~)
Which is nice in that it actually shows the Greek character beta. If I render to gitbook or other HTML it looks as expected. However if I render it to LaTeX (book down::pdf_book) the beta is totally missing:
The options given to pandoc for conversion, via tex to pdf
The use of a UTF-8 font that supports the Greek and math symbols, which may have to be specified
Even in the tex file used to generate the image, there's a slight misstatement about direct Unicode. What was actually entered was ȃ ≅Ŷ, but the rendering dropped the ≅symbol.
I think you have two additional unpalatable choices in addition to the one you identified, which isn't actually that bad given that stringr handles Unicode pretty well:
Run your Rmd files from the command line and call knitr with your own pandoc flags, which basically means reverse engineering from a tex that outputs what you want.
Edit the tex files, but no one is that masochistic.
Here's the tex file I used:
% Input to XeLaTeX is full Unicode, so Unicode characters can be typed directly into the source.
\documentclass[12pt]{article}
\usepackage{fontspec}
\usepackage{graphicx}
\usepackage{amssymb}
\newfontfamily\unicodefont{Lucida Grande}
\title{Greek unicode in R Markdown}
\author{Richard Careaga}
%\date{}
\begin{document}
\maketitle
we get the coefficients (*β*~*i*~) raw (in your example)
we get the coefficients (\emph{β}\textsubscript{\emph{i}}) after plain pandoc conversion
or we get ($\beta \thicksim i$) in native tex, with XeLaTeX engine, but not pdflatexmk
Here is some direct Unicode: ȃ ≅Ŷ in the tex file
\end{document}
Oh, one other thing. \tilde positions atop the preceding character, you need \thicksim for a standalone.
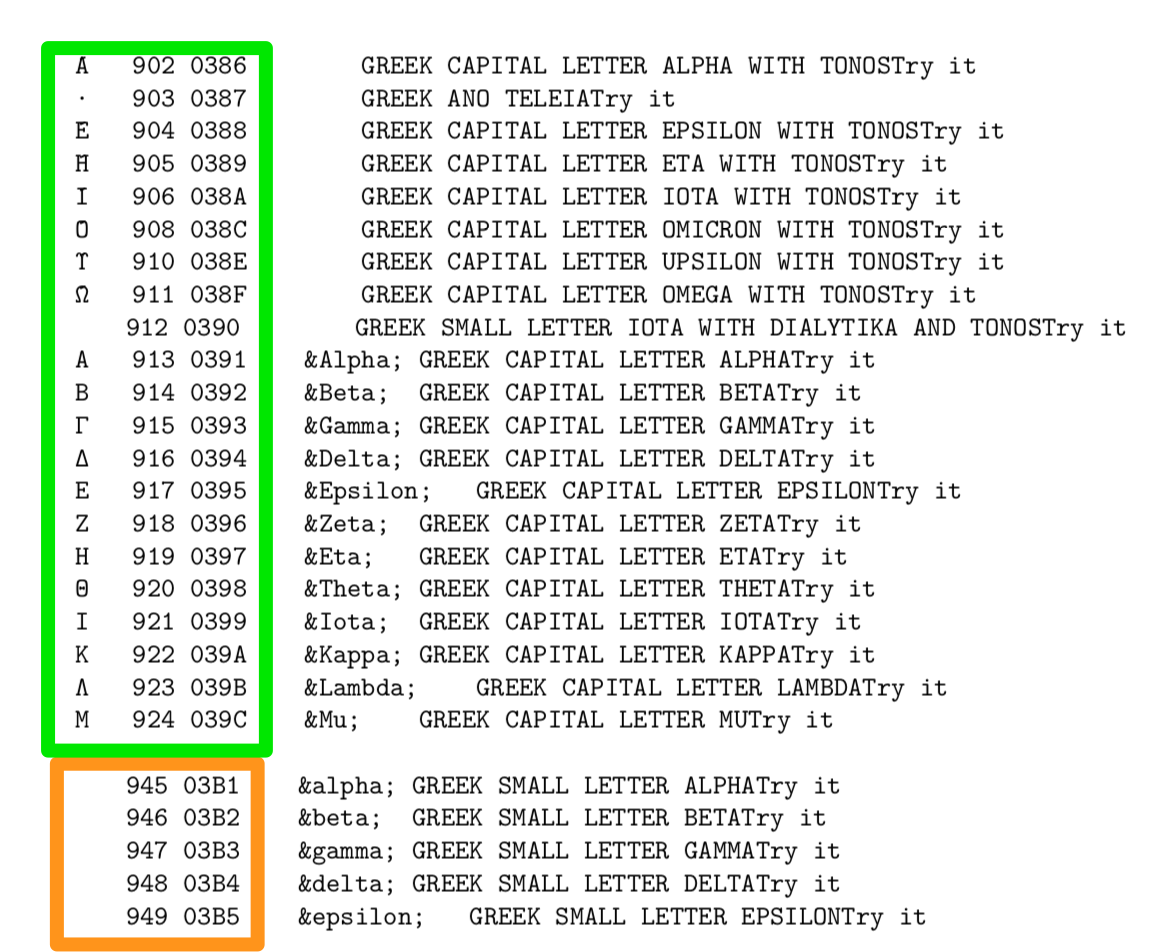
I copied and pasted the whole greek UTF-8 table from here into my book just for testing. All the greek characters render fine in HTML but with XeLeTeX only some of them do.
You can see in this subset (colored boxes added for emphasis) that the core uppercase greeks work fine but not the lowercase:
Interestingly, this is the case whether I surround the text with code ticks ``` or not. Even though code text uses a different font than body text.
So I decided that this must be a font issue. After re-reading a lot of the Bookdown book I realized that I can change the font by changing a few settings in my index.Rmd file. So as an experiment I added the following to my YAML:
Future travelers should note that the above font options are ONLY applicable when using XeLaTeX... other LaTeX engines use different options to change fonts.
Then when I rendered my book to PDF all worked as expected:
XeLaTeX is supposed to allow direct unicode entry in the source, but it depends on which source editor one uses is my best guess from multiple experimentation.