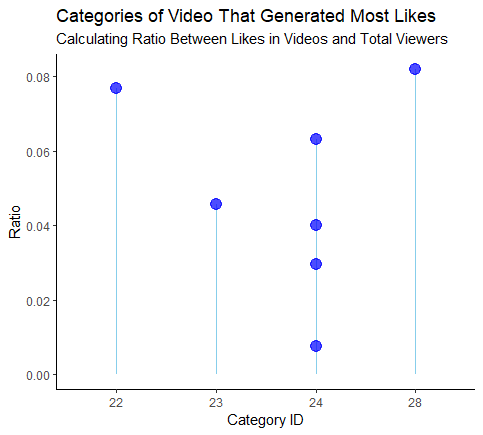
There's df called Youtube video trending, and I tried to find the most likes and dislikes video based on category_id. But I have some problem that hard to crack and find solution because I'm kinda new in Data Analyst world. If you guys can helps me that would be great! Here's the code:
youtube %>%
group_by(category_id) %>%
mutate(ratio = likes/views,
category_id = fct_reorder(category_id, ratio)) %>%
unique() %>%
head(7) %>%
ggplot(aes(category_id, ratio)) +
geom_segment(aes(x = category_id, xend = category_id,
y = 0, yend = ratio), color = "skyblue") +
geom_point(color = "blue", size = 4, alpha = .7) +
labs(x = "Category ID",
y = "Ratio",
title = "Categories of Video That Generated Most Likes",
subtitle = "Calculating Ratio Between Likes in Videos and Total Viewers") +
theme_classic()
What I want is the graph to make different and unique x-axis each values, but instead, why the x-axis value of 24 clumping each other like that?
p.s: I already check unique values in categories_id and indeed there's only one 24 value in categories_id meaning there's no duplicate. But somehow my calculating still add 24 as four different values, beside unique() I already used dplyr::distinct() and the result still the same.
It may be consider style choice, but for me its just more reliably easier to write better code and avoid mistakes to explicitly seperate out the data manipulations that lead up to drawing a graph, from the graphing code itself.
(primarily because its trivial to look at the frame you pass to the graph code to understand what you are doing)
In my own code, I practically never use a pipe to go into ggplot; I always pass a data.frame with a name.
That said, you didnt provide example data, but it was simple enough for me to quickly produce a trivial example frame to show the effects of the code you wrote and my proposal for an alternative. Hope it helps you.
In addition to the explanation nirgrahamuk already gave: group_by() is (almost) always followed by a functions that aggregate groups, such as summarise(), group_map(), group_nest(), group_split(), group_trim()
This is a perfectly legitimate order of operations: group_by() %>% mutate(). This would be used to calculate a value per row based on a grouped stat, e.g. a grouped ratio.
The actions were just not done correctly in this instance.