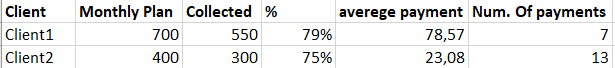I am a junior data analyst at a finance company. We are only 2 in the IT department and both at the start of our carer, that is why I am asking here for advice. In the past, I have created some small app with the help of R and shiny and they were very well accepted. That's also why they trusted me with a new project, that is a bit more challenging. The project is to create an app that shows the progress of the debt collection department. The first page would be a simple overview (table probably) of all clients the goal for the moth the realized amount and some other statistics something like this:
And when one would click on the client it would open another page with detailed data about the collection of that client with advanced statistics and graphs.
My main question is about how to access the data. What are good practices here?
Do I just connect shiny to the main database write a bunch of SQL statements and process and store everything in the data frames and variables inside r? Maybe I am wrong here, but one of the concerns is that this way would “jam” the connection to the database since shiny is reactive?
Is it a better practice to create views on the database that will store the pre-processed data and that way the number of SQL queries of R in the database would be minimal?
The optimal way would be that when a new client is added in the database, it would be automatically in the shiny app so that the clients would not be hard coded.
Are there any other options? How would you guys address this issue?
Every advice is welcome! And thank you!
Well, of course, it depends. How big is the database, how often does it change, and how often are reports needed?
Assuming that this is a periodic, rather than a real time project (time to hire a data engineer); bring your query into a tibble (maybe you can cron this during the day), process, format reports with RMarkdown, deploy to Shiny,
If you volume is moderately high, consider RStudio Server (disclosure:I get nothing from them except great open source software that everyone else does).
Finally, although I'm far from expert, cloud your data base and all you have to worry about is net latency. The data from Redshift, say, will come faster than you can swallow it.
In my view, the point of using R is to limit DB work to storing the data--bring as much as you need into R and work there,
I would like to add to technocrat's answer that this is going to depend on what your limiting resource is (the sql server processing power, memory in the shiny server, etc), on a reasonable scenario your sql server would be able to handle some idle connections just fine but if you choose to make just one big query and store data in memory for the app, your loading time is going to increase as well as your memory requirements and that would make real-time data acquisition inadequate, so as you can see this is a tradeoff and you need to set your priorities first.
Considering the size of today’s databases our would be considered relatively small. It would be nice that the data in the app would be up to date, since the app will be used for agents to see their monthly / weekly / daily progress. It does not have to be instant, but it would be good if it would be quite frequent.
About this part, views don't store pre-processed data, just store the query, maybe you want to take a look into materialized views, which cache data to speed up commonly used queries at the sacrifice of having the most up-to-date data
Thank you for your advice. In my case, the limiting resource would be the memory of the shiny server rather than the Oracle SQL server. Currently already developed shiny apps are running on a computer in the office. I will also take a look into materialized views. Thank you.