I am modeling the effect of turbidity over plankton and the dataset used to is an output of a meta-analysis. I did not manage to model through metafor R package since my model has both a random factor and non-normally distributed data and residuals, so glmm in lmer4 seems to be a way to do so.
I have been trying to fit this glmm model with lme4 package with a dataset that has several negative values at the response variable (yi).
My dataset is composed by ID, the studies identification, yi, the mean effect size, and vi, the variance of effect size.
Here´s how it looks like:
ID
yi
vi
1
0.316595198
0.04821567
1
-0.177368318
0.04780631
11
-0.981140624
0.08721714
11
-0.922435838
0.08827934
11
-0.786731923
0.16784691
11
-1.086341767
0.11456009
11
-1.410975938
0.15027751
11
-1.141576723
0.11595849
11
-0.737618762
0.08194444
11
-0.690005397
0.08336584
This is a sample of the data. the whole set looks like this:
What is the correct family to indicate at this model?
yi mean is -1,04
Also: How can I make this model run since there seems not to have a way to make glmer handle negative values?
Thank you for the indication. I inserted poisson family just for not letting the code empty, to compose an example, but now I see that this was not a good idea. I edited the question to make it more comprehensible.
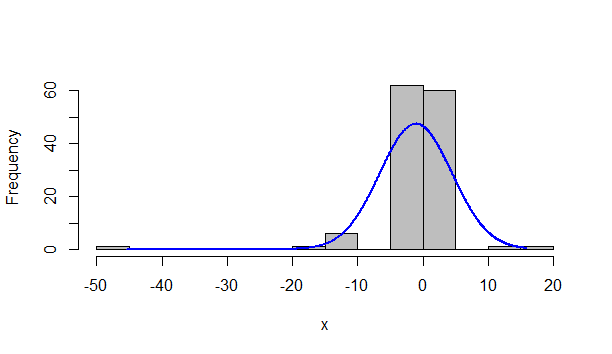
Problem knowledge is all important here. What would you expect the response variable to have as a distribution? Looking only at the data, I'd be tempted to say a Gaussian, in which case you want an lmer() model rather than a glmer() model. The large negative values need to be addressed - are they real or outliers? If they're real, then the Gaussian might not be appropriate, but if you think there might be a problem in the data (gasp!) then you might consider dropping those points. Then again, the histogram looks rather "peaky", so maybe another distribution would be appropriate.
This doesn't address the issue of generating a way to model the data with glmer(), I do realise. But the key issue is to understand what the data is supposed to behave like (if indeed that's possible) and then build the model to fit that behaviour.
Thank you for the answer. Ths is actually what the data are supposed to be like, since it results from calculations made over naturally skewed and spreaded (tailed) data.
The general advice in this situation if a mixed effects model is required is to consider applying a transformation to stabilise the variance. A power law is helpful, a log-transformation obviously won't work. Be careful with the inverse transformation - Harell ("Regression modelling strategies") can be a helpful book.