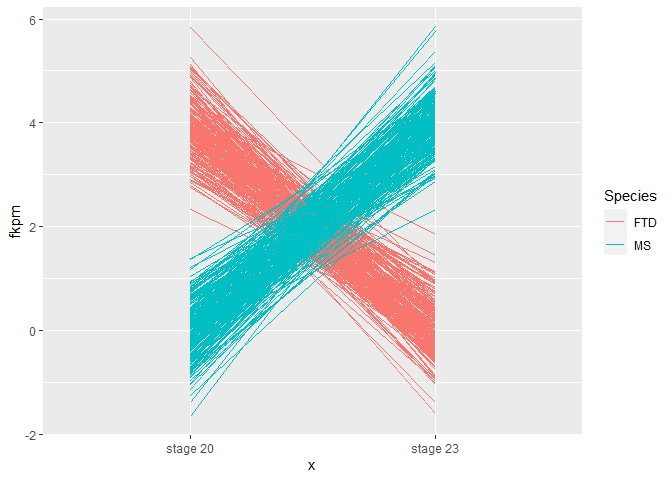
Hi R community,
I'm looking to create a plot (probably using geom_line()) with the following information:
- The x axis contains two points (Age 1 and Age 2). These are technically discrete, but I have expressed them in the example below as continuous so that I can use
geom_line(). - The y axis is also continuous (some value denoting 'intensity' - in this instance it is regarding the level of gene expression, fpkm values)
- The data is organised by another categorical variable (species) of which there are two (MS and FTD)- this should be mapped to the
coloraesthetic. - Each line on the graph should correspond to another categorical variable (the gene of interest).
Now, this may not be "best practice" or whatever, but it is what I need to achieve. My data is in a long format currently, with each row representing one observation (for the continuous variable mapped to y, fpkm) and columns representing the other variables (one variable per column) - species, gene, age.
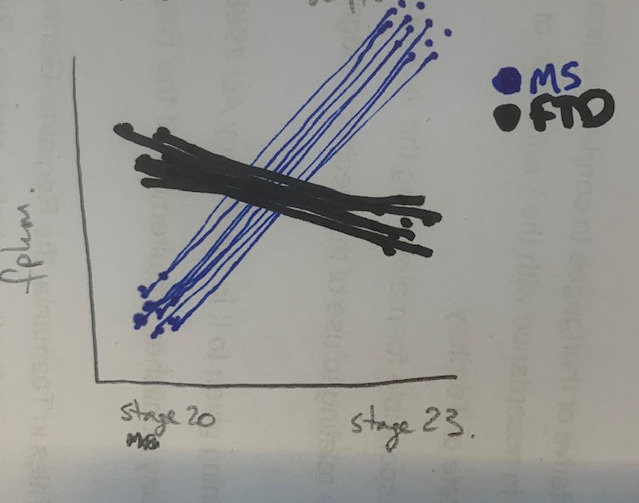
I've attached an sketch of what the graph should look like: note, each line is connecting the value for the variable fpkm across the two ages. Being able to distinguish the individual lines is not important, but I don't want to express this as an average.
So a reprex:
library(reprex)
#some data of equivalent format
Age <- rep(1:2, 60)
Species <- c(rep("FTD", 30),rep("MS", 30))
fpkm <- sample(1:10, size = 60, replace = TRUE)
geneID <- c(rep(c(1:15), each = 2),rep(c(1:15), each = 2))
df <- data.frame(Age, Species, fpkm, geneID)
library(ggplot2)
#incorrect plotting
ggplot(df, aes(x = Age, y = fpkm, color = Species, group = geneID)) +
geom_line()
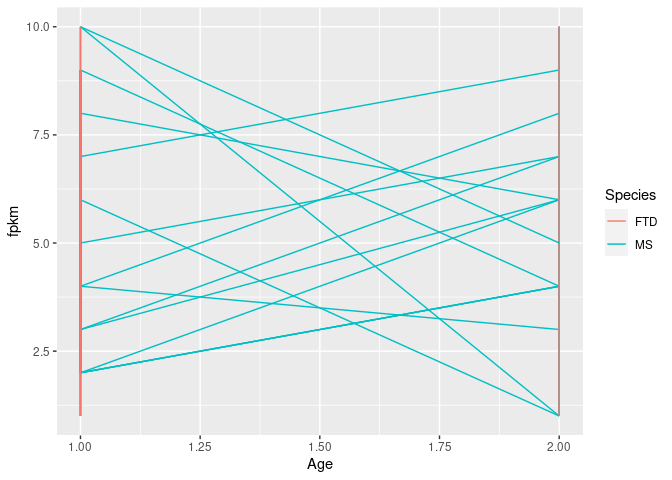
Created on 2020-09-02 by the reprex package (v0.3.0)
I'm not worried about the labelling of the x-axis, but for some reason the colouring doesn't seem to map correctly?
I've tried to put the color aesthetic in the geom_line() call but this didn't help. geom_point() seems to generate the data correctly, but then if I try to draw lines between the points (which would be the ideal graph) it performs similar to the above.... I'm not really sure why this is the case and would appreciate some help!
As a note, I am looking to generate this graph for 100s of genes, so manual entry is not an option (I experimented with some for loops for this but to no avail)
thanks