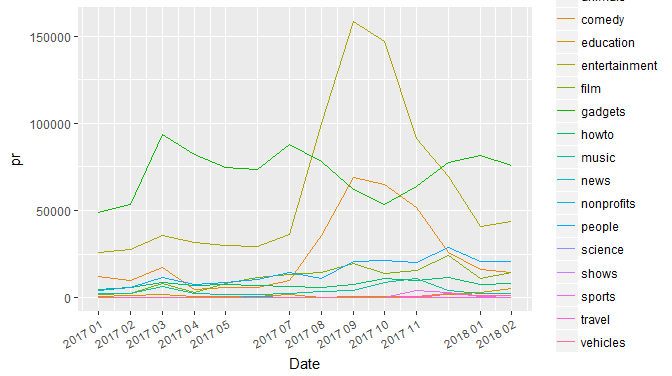
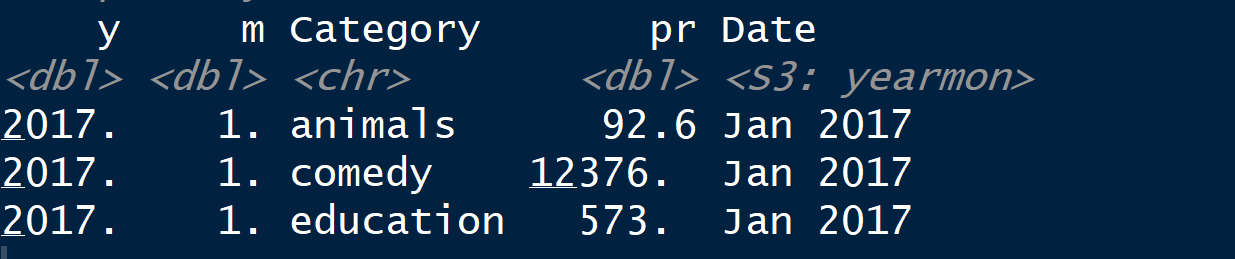
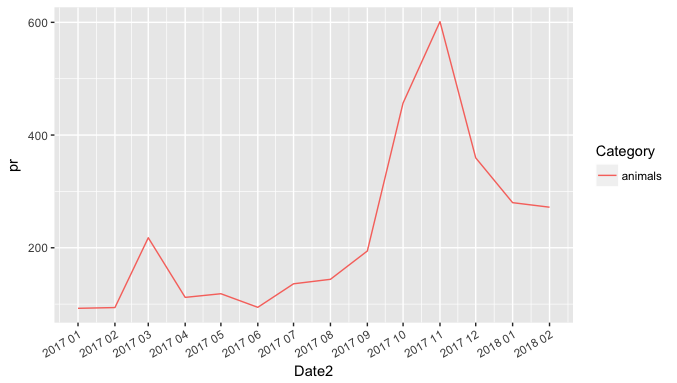
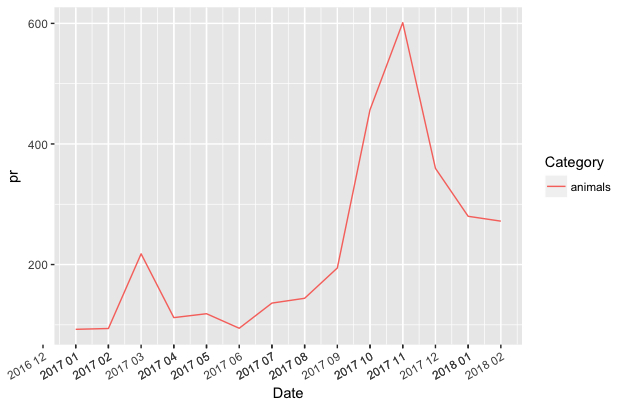
> dput(catdata[catdata$Category=="animals", ]
structure(list(y = c(2017, 2017, 2017, 2017, 2017, 2017, 2017,
2017, 2017, 2017, 2017, 2017, 2018, 2018), m = c(1, 2, 3, 4,
5, 6, 7, 8, 9, 10, 11, 12, 1, 2), Category = c("animals", "animals",
"animals", "animals", "animals", "animals", "animals", "animals",
"animals", "animals", "animals", "animals", "animals", "animals"
), pr = c(92.560799, 93.895604, 217.773775, 111.958975, 118.432367,
94.326318, 136.052199, 144.02308, 194.307174, 456.824091, 601.234364,
359.550693, 280.035412, 271.973927), Date = structure(c(2017,
2017.08333333333, 2017.16666666667, 2017.25, 2017.33333333333,
2017.41666666667, 2017.5, 2017.58333333333, 2017.66666666667,
2017.75, 2017.83333333333, 2017.91666666667, 2018, 2018.08333333333
), class = "yearmon")), .Names = c("y", "m", "Category", "pr",
"Date"), row.names = c(NA, -14L), class = c("grouped_df", "tbl_df",
"tbl", "data.frame"), vars = c("y", "m"), drop = TRUE, indices = list(
0L, 1L, 2L, 3L, 4L, 5L, 6L, 7L, 8L, 9L, 10L, 11L, 12L, 13L), group_sizes = c(1L,
1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L), biggest_group_size = 1L, labels = structure(list(
y = c(2017, 2017, 2017, 2017, 2017, 2017, 2017, 2017, 2017,
2017, 2017, 2017, 2018, 2018), m = c(1, 2, 3, 4, 5, 6, 7,
8, 9, 10, 11, 12, 1, 2)), row.names = c(NA, -14L), class = "data.frame", vars = c("y",
"m"), drop = TRUE, .Names = c("y", "m")))
I hope that helps