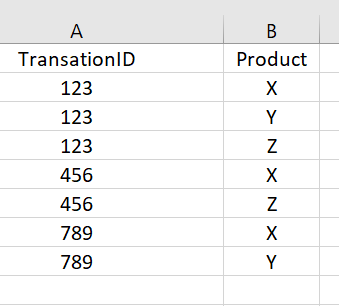
Dear all,
Sorry in advance if my question looks too basic.
What would be the best approach (function, library) if I wish to extract only the order, where product X and Y has been bought but within the same order ?
Example output below is transactionID 123 and 789
Thanks again for your help,
It would be easier to help you if you provide a REPR oducible EX ample (reprex)
library(dplyr)
library(stringr)
set.seed(1)
sample_data <- data.frame(transaction_id = sample(1:3, 7, replace = TRUE),
product = sample(c("X", "Y", "Z"), 7, replace = TRUE))
sample_data %>%
arrange(transaction_id)
#> transaction_id product
#> 1 1 Y
#> 2 1 Z
#> 3 1 X
#> 4 2 Z
#> 5 3 Y
#> 6 3 X
#> 7 3 X
sample_data %>%
arrange(transaction_id) %>%
group_by(transaction_id) %>%
summarise(product = paste(product, collapse = ",")) %>%
filter(str_detect(product, "[XY]{1}.*[XY]{1}"))
#> # A tibble: 2 x 2
#> transaction_id product
#> <int> <chr>
#> 1 1 Y,Z,X
#> 2 3 Y,X,X
Created on 2019-10-17 by the reprex package (v0.3.0.9000)
2 Likes
Logic is perfect - thanks a lot
system
October 25, 2019, 12:27pm
4
This topic was automatically closed 7 days after the last reply. New replies are no longer allowed.