Hi everyone,
I am looking for some idea of how to solve this situation in R.
The case is: I have a GPS track of a person by bike, in which there are around 5000 waypoints with their respective ID (consecutive from 1 to n), Longitude, Latitude, and Time (in which the waypoint was taken).
In this data set, I need to identify when the person on the bike is not moving (maybe because got tired, or whatever) having in consideration the error of the GPS, that means, even tho the object is not in movement, and there was for example 5 waypoints taken while the person was standing there, there could be few meters distance between those 5 points.
The guy in the bike passed through the same place several times in different time, which means that could be points near each other, but not related because one point was taken later.
My proposal was to measure distance between consecutive points (1 to 2, 2 to 3, 3 to 4 , … , n-1 to n), and then subset those points where the distances was les tan k (1.5 metes for example), i have created a group of consecutive points (when the consecuttive is broken, the next rows Will belong to the following group, and so on), giving a new table.
The last step is to aggregate by cluster of the points, to identify from which point to which point, the object apparently was not moving, giving the following result:
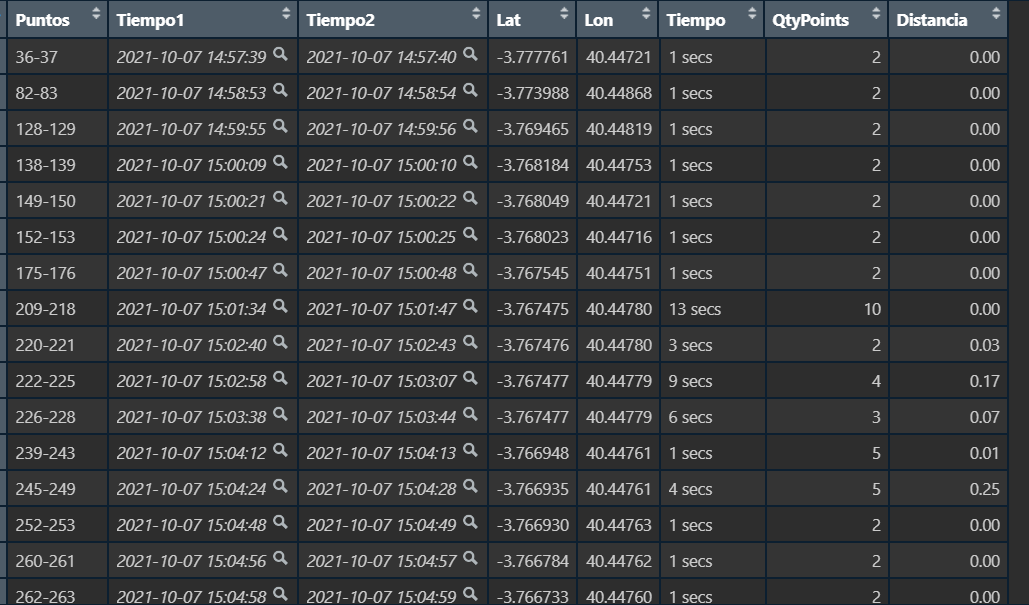
The problem is that I am not convince that this is the best way to do it.
My question is, is the any other way feasible to do it?
I put here the data and my code, in case someone want to help me with this!
Thanks in advance!
pacman::p_load(data.table, chron, lubridate, rgdal, sf, ggplot2, rgeos, mapview, dplyr, kableExtra, tidyr, stringr, textshape)
setwd("C:/Users/Walbersy/Desktop/Documentos/Practica/Geographical/Bike_activity")
points <- read_sf('Bike_activity.shp')
points_sampled<-read.csv("Bike_activity.csv")
track <- read_sf('Bike_activity_track.shp')
for (i in 2:nrow(points_sampled)) {
points_sampled$distancia[[i-1]] <- distm(c(points_sampled[(i-1),4],
points_sampled[(i-1),5]), c(points_sampled[i,4],
points_sampled[i,5]), fun = distHaversine)
points_sampled$distancia <- round(as.numeric(points_sampled$distancia), digits =2)
}
points_near <- data.frame(matrix(ncol = 8, nrow = 0))
x <- c("Puntos", "Tiempo_1", "Tiempo_2", "Distancia", "Lat1", "Lon1", "Lat2", "Lon2")
colnames(points_near)<-x
for (i in 2:nrow(points_sampled)) {
points_near[i-1,] <- data.frame(Puntos = paste(points_sampled[[1]][[i-1]],
points_sampled[[1]][[i]], sep = "-"),
Tiempo_1 = points_sampled[[3]][[i-1]],
Tiempo_2 = points_sampled[[3]][[i]],
Distancia = points_sampled[[8]][[i-1]],
Lat1= points_sampled[[4]][[i-1]],
Lon1= points_sampled[[5]][[i-1]],
Lat2= points_sampled[[4]][[i]],
Lon2= points_sampled[[5]][[i]])
}
points_stay <- subset(points_near, Distancia < 1)
points_stay$consecutivo1 <- sub("\\-.*","", points_stay$Puntos)
points_stay$consecutivo2 <- sub(".*-","", points_stay$Puntos)
points_stay$consecutivo1 <- as.numeric(points_stay$consecutivo1)
points_stay$consecutivo2 <- as.numeric(points_stay$consecutivo2)
points_stay<-data.frame(points_stay, IdCluster = cumsum(c(1L, diff(points_stay$consecutivo1) > 1L)))
##--
##points_stay_bc <- points_stay
##points_stay <- points_stay_bc
points_stay <- subset(points_stay, Distancia <= 0.3)
points_stay<-data.frame(points_stay, IdCluster2 = cumsum(c(1L, diff(points_stay$consecutivo1) > 1L)))
points_stay<-points_stay%>%
group_by(IdCluster2)%>%
summarise(Punto1 = min(consecutivo1), Punto2 = max(consecutivo2), Tiempo1 = min(Tiempo_1), Tiempo2 = min(Tiempo_2), Lat = mean(Lat1), Lon = mean(Lon1), Distancia = max(Distancia))
points_stay$Tiempo1<-gsub("/","-", points_stay$Tiempo1)
points_stay$Tiempo1<-strptime(points_stay$Tiempo1, format = "%Y-%m-%d %H:%M:%S",tz="UTC")
points_stay$Tiempo2<-gsub("/","-", points_stay$Tiempo2)
points_stay$Tiempo2<-strptime(points_stay$Tiempo2, format = "%Y-%m-%d %H:%M:%S",tz="UTC")
points_stay$Puntos <- paste(points_stay$Punto1, points_stay$Punto2, sep = "-")
points_stay$Tiempo <- points_stay$Tiempo2 - points_stay$Tiempo1
points_stay$QtyPoints <- (points_stay$Punto2 - points_stay$Punto1)+1
points_stay <- points_stay[,c(9,4,5,6,7,10,11,8)]
write.csv(points_stay, "points_stay.csv", row.names = FALSE)
data can be found here: