I have a panel dataset of 908 cities (aka metros) with monthly median house value (from Zillow) for each city.
rm(list = ls());
library(readr); #read_csv
library(reshape2); #melt() converts wide to long
library(dplyr); #summarise by group etc. #lag
url = 'https://files.zillowstatic.com/research/public_csvs/zhvi/Metro_zhvi_uc_sfrcondo_tier_0.33_0.67_sm_sa_month.csv';
z = read_csv(url, col_names = TRUE)
z = subset(z, select = -c(SizeRank, RegionID, RegionType, StateName) )
z = melt(z, id=c("RegionName")) #Now reshaped into panel.
colnames(z)[colnames(z)=="variable"] <- "date"
colnames(z)[colnames(z)=="value"] <- "hp"
colnames(z)[colnames(z)=="RegionName"] <- "metro"
z$year = substr(z$date, 1, 4) #create year
The data for each metro begins "Jan-2000" and continues until the present.
How can I create the following variables/columns for each metro:
(this should prob be a new DataFrame where the first column is metro and each row is a unique metro)
hp_max_boom: the maximum value of hp in each metro between "Jan-2000" and "Dec-2007"
hp_min_boom: the minimum value of hp in each metro between "Jan-2000" and "Dec-2007"
hp_min_bust: the minimum value of hp in each metro between "Jan-2006" and "Dec-2012"
hp_max_recovery: the maximum value of hp in each metro between "Jan-2010" and "Dec-2019"
I would make summary data frames like the following Boom and then join them.
library(tidyverse)
#> Warning: package 'tibble' was built under R version 4.1.2
library(lubridate)
url = 'https://files.zillowstatic.com/research/public_csvs/zhvi/Metro_zhvi_uc_sfrcondo_tier_0.33_0.67_sm_sa_month.csv';
z = read_csv(url, col_names = TRUE)
#> Rows: 908 Columns: 271
#> -- Column specification --------------------------------------------------------
#> Delimiter: ","
#> chr (3): RegionName, RegionType, StateName
#> dbl (268): RegionID, SizeRank, 2000-01-31, 2000-02-29, 2000-03-31, 2000-04-3...
#>
#> i Use `spec()` to retrieve the full column specification for this data.
#> i Specify the column types or set `show_col_types = FALSE` to quiet this message.
z = subset(z, select = -c(SizeRank, RegionID, RegionType, StateName) )
z <- pivot_longer(z,cols = -RegionName,names_to = "date",values_to = "hp")
z <- rename(z,metro="RegionName")
z$date <- ymd(z$date) #make the dates numeric
z$year <- year(z$date)
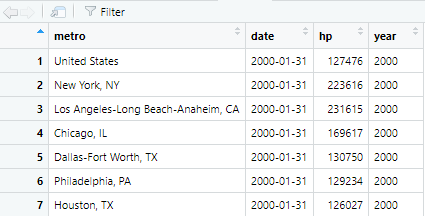
head(z)
#> # A tibble: 6 x 4
#> metro date hp year
#> <chr> <date> <dbl> <dbl>
#> 1 United States 2000-01-31 127476 2000
#> 2 United States 2000-02-29 127820 2000
#> 3 United States 2000-03-31 128183 2000
#> 4 United States 2000-04-30 128921 2000
#> 5 United States 2000-05-31 129666 2000
#> 6 United States 2000-06-30 130409 2000
Boom <- z |> filter(year >= 2000, year <= 2007) |>
group_by(metro) |>
summarize(hp_max_boom = max(hp,na.rm = TRUE),
hp_min_boom = min(hp,na.rm = TRUE))
head(Boom)
#> # A tibble: 6 x 3
#> metro hp_max_boom hp_min_boom
#> <chr> <dbl> <dbl>
#> 1 Aberdeen, SD -Inf Inf
#> 2 Aberdeen, WA -Inf Inf
#> 3 Abilene, TX -Inf Inf
#> 4 Ada, OK 77860 54325
#> 5 Adrian, MI 147438 113120
#> 6 Akron, OH 141922 117046
Created on 2022-03-11 by the reprex package (v2.0.1)
After making a similar data frame for the Bust data, join them like this: