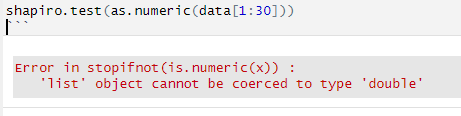
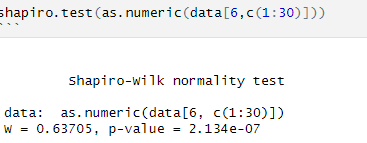
When starting with an example data.frame like this:
(iris_head <- head(iris))
#> Sepal.Length Sepal.Width Petal.Length Petal.Width Species
#> 1 5.1 3.5 1.4 0.2 setosa
#> 2 4.9 3.0 1.4 0.2 setosa
#> 3 4.7 3.2 1.3 0.2 setosa
#> 4 4.6 3.1 1.5 0.2 setosa
#> 5 5.0 3.6 1.4 0.2 setosa
#> 6 5.4 3.9 1.7 0.4 setosa
, you could iterate over rows of the relevant subset with apply() and get a list of htest objects, one for each row:
shap_lst <- apply(iris_head[1:4], MARGIN = 1, shapiro.test)
str(shap_lst)
#> List of 6
#> $ 1:List of 4
#> ..$ statistic: Named num 0.969
#> .. ..- attr(*, "names")= chr "W"
#> ..$ p.value : num 0.838
#> ..$ method : chr "Shapiro-Wilk normality test"
#> ..$ data.name: chr "newX[, i]"
#> ..- attr(*, "class")= chr "htest"
#> $ 2:List of 4
#> ..$ statistic: Named num 0.982
#> .. ..- attr(*, "names")= chr "W"
#> ..$ p.value : num 0.914
#> ..$ method : chr "Shapiro-Wilk normality test"
#> ..$ data.name: chr "newX[, i]"
#> ..- attr(*, "class")= chr "htest"
#> $ 3:List of 4
#> ..$ statistic: Named num 0.971
#> .. ..- attr(*, "names")= chr "W"
#> ..$ p.value : num 0.846
#> ..$ method : chr "Shapiro-Wilk normality test"
#> ..$ data.name: chr "newX[, i]"
#> ..- attr(*, "class")= chr "htest"
#> $ 4:List of 4
#> ..$ statistic: Named num 0.987
#> .. ..- attr(*, "names")= chr "W"
#> ..$ p.value : num 0.94
#> ..$ method : chr "Shapiro-Wilk normality test"
#> ..$ data.name: chr "newX[, i]"
#> ..- attr(*, "class")= chr "htest"
#> $ 5:List of 4
#> ..$ statistic: Named num 0.963
#> .. ..- attr(*, "names")= chr "W"
#> ..$ p.value : num 0.796
#> ..$ method : chr "Shapiro-Wilk normality test"
#> ..$ data.name: chr "newX[, i]"
#> ..- attr(*, "class")= chr "htest"
#> $ 6:List of 4
#> ..$ statistic: Named num 0.968
#> .. ..- attr(*, "names")= chr "W"
#> ..$ p.value : num 0.831
#> ..$ method : chr "Shapiro-Wilk normality test"
#> ..$ data.name: chr "newX[, i]"
#> ..- attr(*, "class")= chr "htest"
Those can be converted to a frame and added to your dataset, if needed:
# drop htest class for bind_rows()
shap_df <- lapply(shap_lst, unclass) |> dplyr::bind_rows()
shap_df
#> # A tibble: 6 × 4
#> statistic p.value method data.name
#> <dbl> <dbl> <chr> <chr>
#> 1 0.969 0.838 Shapiro-Wilk normality test newX[, i]
#> 2 0.982 0.914 Shapiro-Wilk normality test newX[, i]
#> 3 0.971 0.846 Shapiro-Wilk normality test newX[, i]
#> 4 0.987 0.940 Shapiro-Wilk normality test newX[, i]
#> 5 0.963 0.796 Shapiro-Wilk normality test newX[, i]
#> 6 0.968 0.831 Shapiro-Wilk normality test newX[, i]
# add statistic & p.value columns to iris_head
cbind(iris_head, shap_df[,1:2])
#> Sepal.Length Sepal.Width Petal.Length Petal.Width Species statistic p.value
#> 1 5.1 3.5 1.4 0.2 setosa 0.9694987 0.8383766
#> 2 4.9 3.0 1.4 0.2 setosa 0.9820427 0.9138954
#> 3 4.7 3.2 1.3 0.2 setosa 0.9707126 0.8458912
#> 4 4.6 3.1 1.5 0.2 setosa 0.9867607 0.9403457
#> 5 5.0 3.6 1.4 0.2 setosa 0.9627830 0.7964093
#> 6 5.4 3.9 1.7 0.4 setosa 0.9683317 0.8311267