I'm new to R, and need some help. Basically what I have is a list of library call numbers - some come from a list of documents received from elsewhere (Source = State List), and some from our catalog (Source = Alma) - and I need to determine which numbers from the first list are already represented in our catalog.
I've compiled both lists into a dataframe with the source of call number identified:
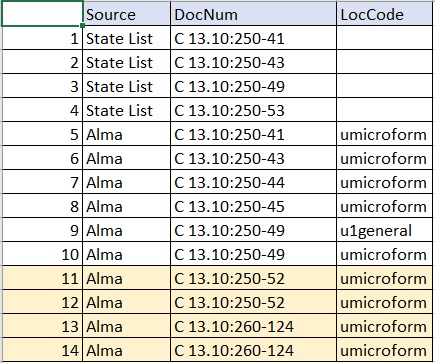
This code gets me all the duplicated call numbers in the dataframe:
govdoc_compare[duplicated(govdoc_compare$DocNum) | duplicated(govdoc_compare$DocNum, fromLast = TRUE),]
but it includes duplicates that are ONLY in the Alma source and don't have a matching call number in the State List Source (like the highlighted lines in my example dataframe above).
Is there a way I can filter out duplicates that only occur in the Alma source, but keep duplicates in Alma that match a call number in the State List source?
Thank you!