I am working with the R programming language.
Suppose I have the following data:
a = rnorm(1000,10,1)
b = rnorm(200,3,1)
c = rnorm(200,13,1)
d = c(a,b,c)
index <- 1:1400
my_data = data.frame(index,d)
I can make the following histograms of the same data by adjusting the "bin" length (via the "breaks" option):
hist(my_data, breaks = 10, main = "Histogram #1, Breaks = 10")
hist(my_data, breaks = 100, main = "Histogram #2, Breaks = 100")
hist(my_data, breaks = 5, main = "Histogram #3, Breaks = 5")
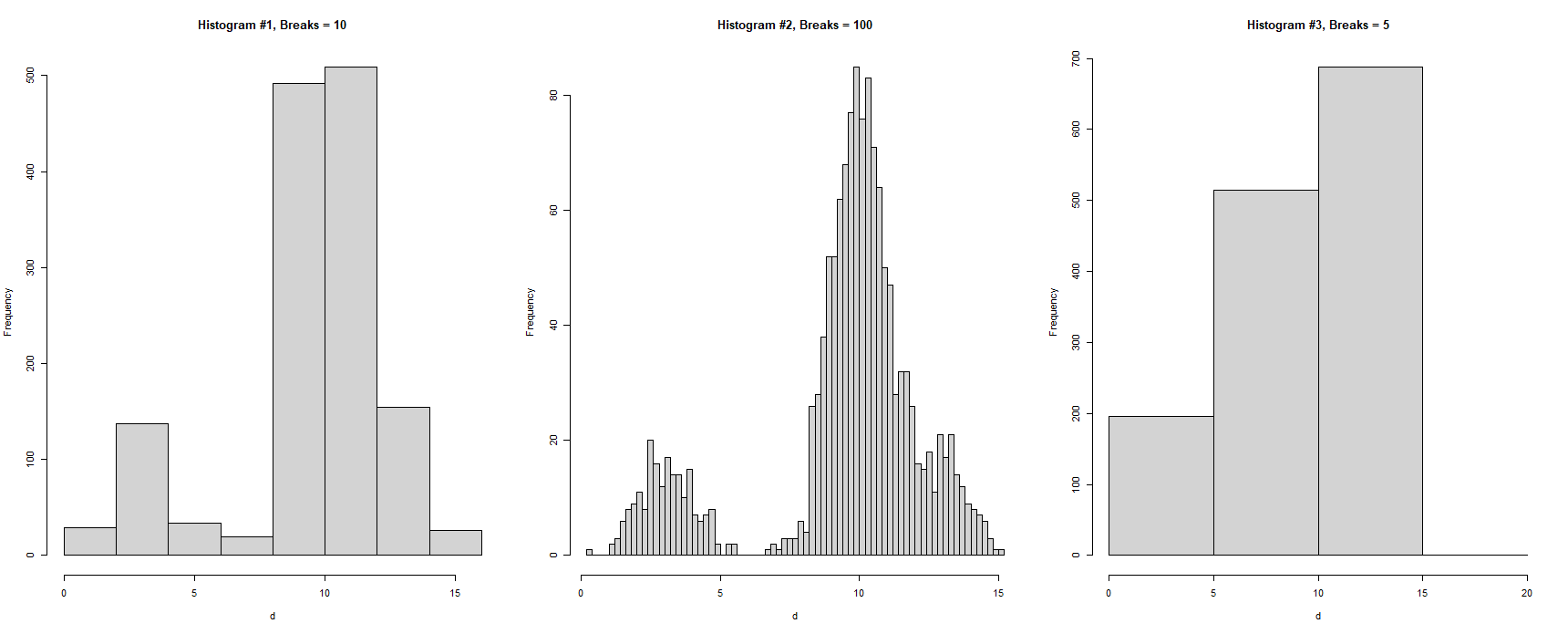
My Question: In each one of these histograms there are a different number of "bars" (i.e. bins). For example, in the first histogram there are 8 bars and in the third histogram there are 4 bars. For each one of these histograms, is there a way to find out which observations (from the original file "d") are located in each bar?
Right now, I am trying to manually do this, e.g. (for histogram #3)
histogram3_bar1 <- my_data[which(my_data$d < 5 & my_data$d > 0), ]
histogram3_bar2 <- my_data[which(my_data$d < 10 & my_data$d > 5), ]
histogram3_bar3 <- my_data[which(my_data$d < 15 & my_data$d > 10), ]
histogram3_bar4 <- my_data[which(my_data$d < 15 & my_data$d > 20), ]
head(histogram3_bar1)
index d
1001 1001 4.156393
1002 1002 3.358958
1003 1003 1.605904
1004 1004 3.603535
1006 1006 2.943456
1007 1007 1.586542
But is there a more "efficient" way to do this?
Thanks!