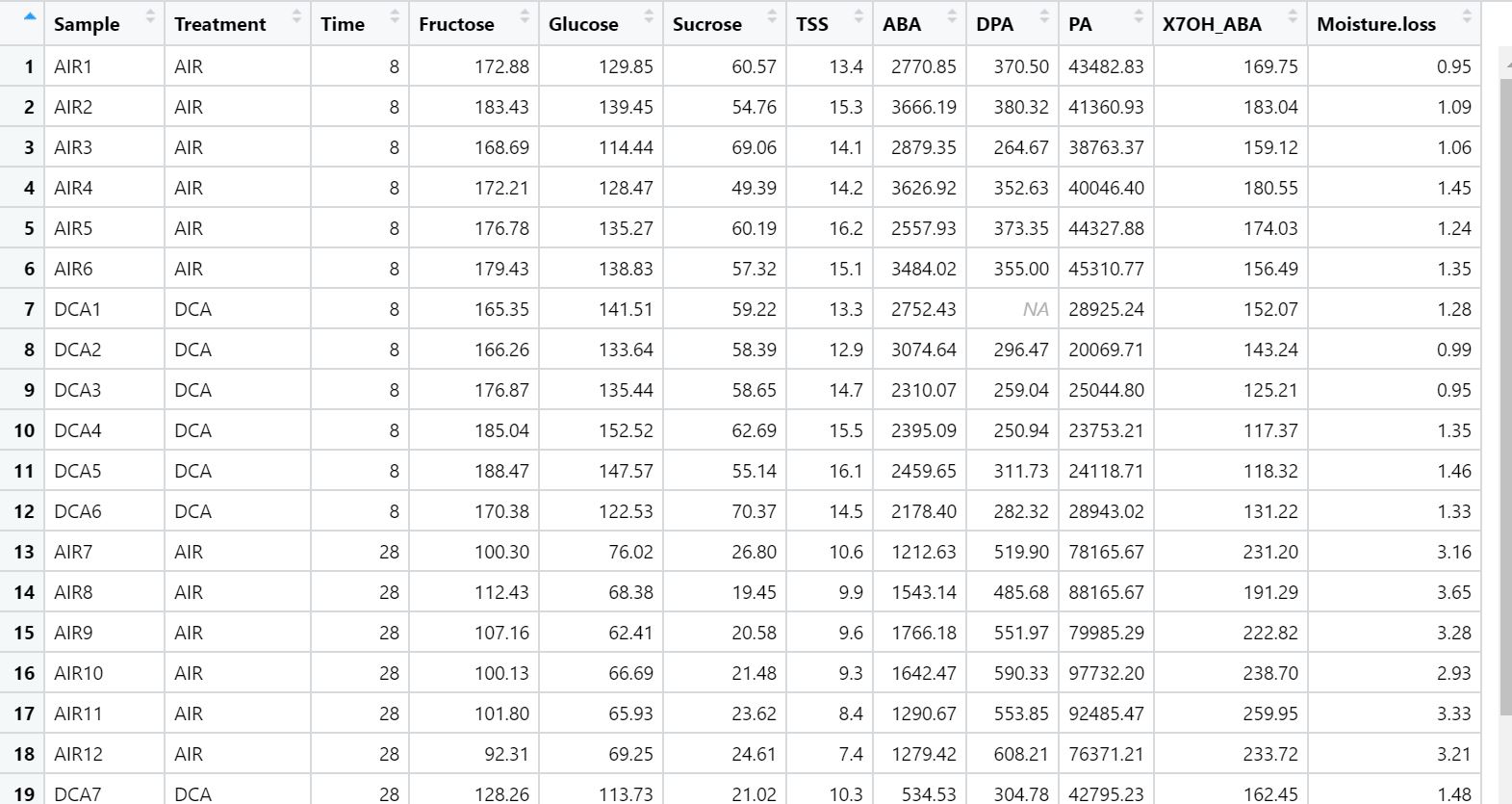
I am doing an MSc and have been given a project task which I can't get my head around. The csv dataset which has 12 columns and 25 rows including the headers. The samples are divided into 4 sets, AIR1-AIR6, DCA1-DCA6 = controls and AIR7-AIR12, DCA7-DCA12.
We have been asked to calculate descriptive stats (mean, median, sd) for the the controls (AIR1-AIR6, DCA1-DCA6) and the data AIR7-AIR12, DCA7-DCA12 to see if there are any differences.
My question is how can I do this in the most simple way in rstudio?
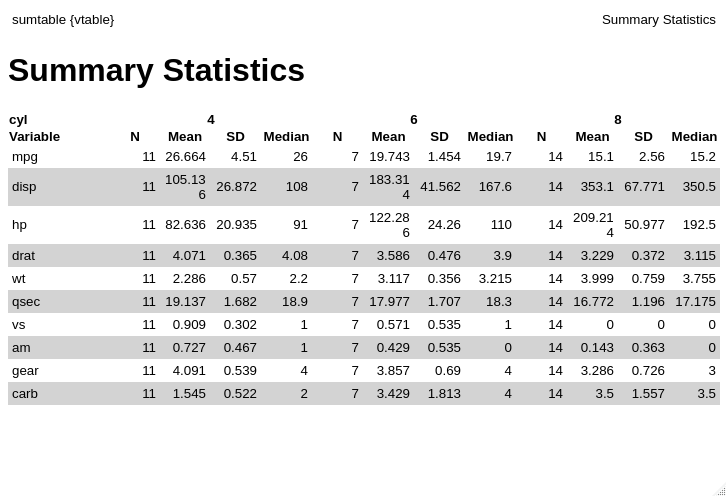
What, that's it? Well, not really. In the R spirit of lazy evaluation I weighed doing this manually versus finding a package for what is really a very common task and learning how to use it. It started with a search of summary statistics on rseek.
I could have done this in base{} simply by
apply(mtcars[which(mtcars$cyl == 4),-2],2,sd)
#> mpg disp hp drat wt qsec vs
#> 4.5098277 26.8715937 20.9345300 0.3654711 0.5695637 1.6824452 0.3015113
#> am gear carb
#> 0.4670994 0.5393599 0.5222330