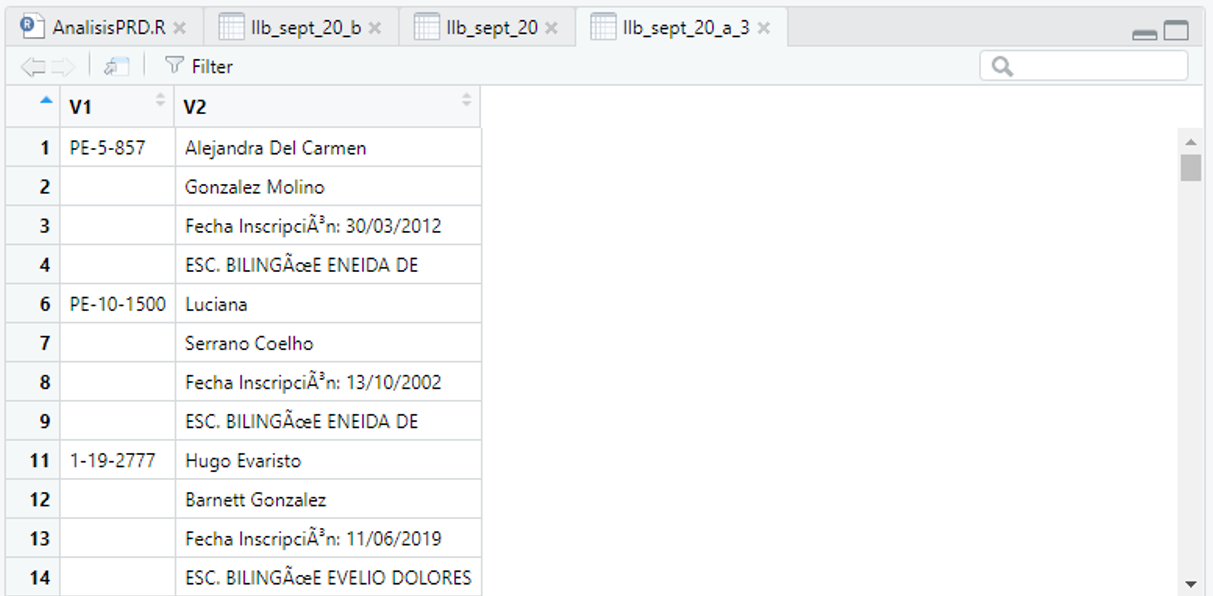
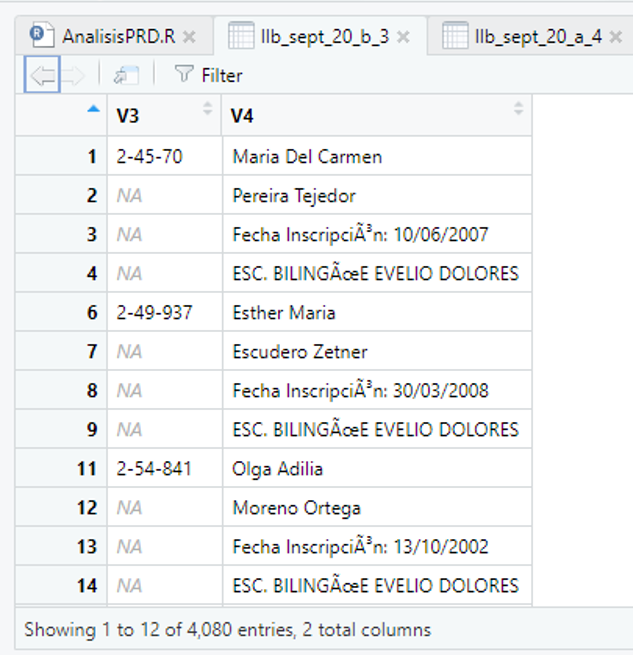
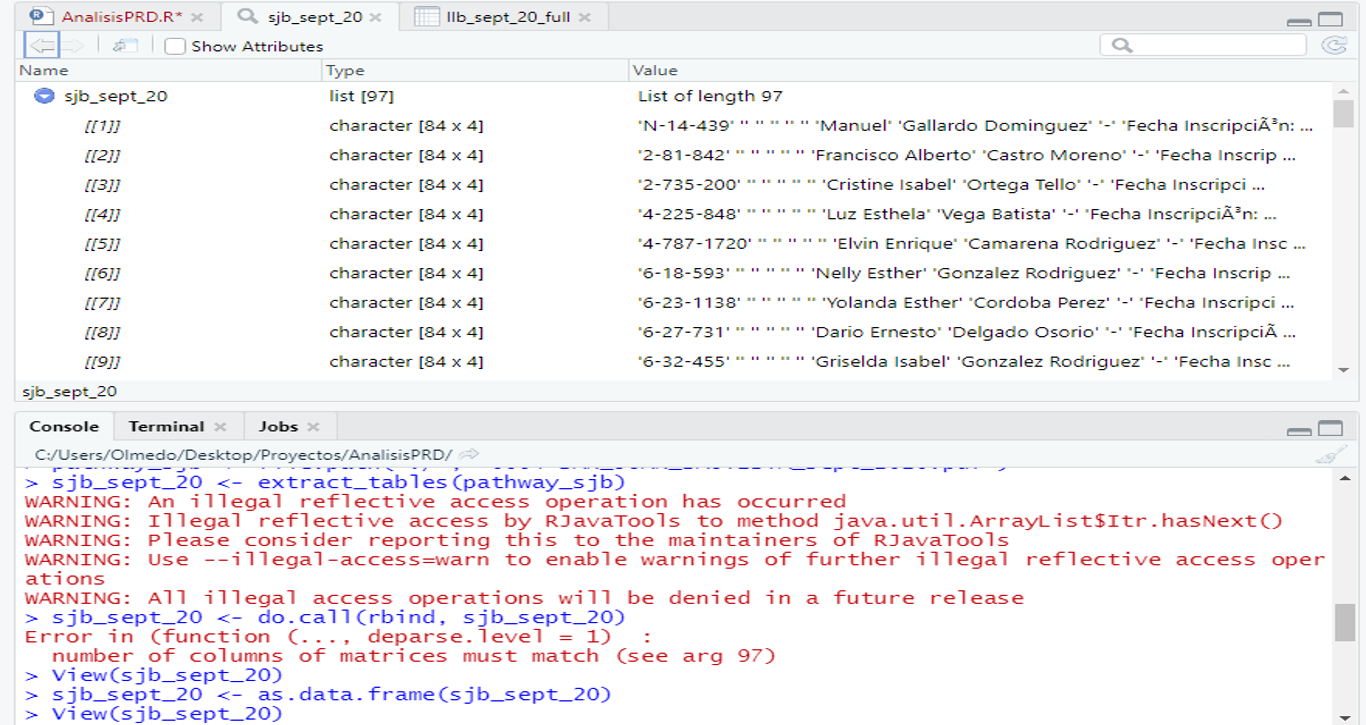
I am new in R and in this forum. I would appreciate anyone´s help. I am trying to manipulate a dataframe to reorder the values that comes from a PDF table. I did the PDF extract tables and it looks as follows.
#Extracting the PDF table
pathway <- file.path("./", "0005-LLANO_BONITO_sept_2020.pdf")
llb_sept_20 <- extract_tables(pathway)
llb_sept_20 <- do.call(rbind, llb_sept_20)
llb_sept_20 <- as.data.frame(llb_sept_20)
Since I do not have your data, I invented a small data set.. The fill() function fills in missing values with the most recent non-missing value so that every row in V1 has a value. The group_by() and Mutate() functions work together to make a new column named ColName that stores the names of the columns that will be made in the next step. You might want to make names that are more informative than V2, V3, etc. The pivot_wider() function pivots the data so there is one row for each value of V1.
library(tidyr)
library(dplyr)
#>
#> Attaching package: 'dplyr'
#> The following objects are masked from 'package:stats':
#>
#> filter, lag
#> The following objects are masked from 'package:base':
#>
#> intersect, setdiff, setequal, union
DF <- data.frame(V1 = c("A", NA,NA,NA,"B",NA,NA,NA,"C",NA,NA, NA),
V2 = c("AA", "BB", "CC", "DD", "EE", "FF", "GG", "HH", "II", "JJ", "KK", "LL"))
DF
#> V1 V2
#> 1 A AA
#> 2 <NA> BB
#> 3 <NA> CC
#> 4 <NA> DD
#> 5 B EE
#> 6 <NA> FF
#> 7 <NA> GG
#> 8 <NA> HH
#> 9 C II
#> 10 <NA> JJ
#> 11 <NA> KK
#> 12 <NA> LL
DFpivot <- DF %>% fill(V1) %>%
group_by(V1) %>%
mutate(ColName = paste0("V",row_number() + 1)) %>%
pivot_wider(names_from = ColName, values_from = V2)
DFpivot
#> # A tibble: 3 x 5
#> # Groups: V1 [3]
#> V1 V2 V3 V4 V5
#> <chr> <chr> <chr> <chr> <chr>
#> 1 A AA BB CC DD
#> 2 B EE FF GG HH
#> 3 C II JJ KK LL
I tried to do the same with a different set of values and did not get the expected results. I modified the code in R to the new variables but it did not work. Let me show you...
The problem is that the code is trying to make duplicate column names. This part of the code,
mutate(ColName = paste0("V",row_number() + 1))
makes the column names V2, V3, V4, V5 if each value of the original V3 spans four rows. You already have a column named V3 and I suppose the function does not allow duplicate column names. The easiest fix is to name the new columns with a letter other than V. Try
Notice that the new column numbering now starts from 1 since I dropped the + 1 from the paste0 function that makes the column names. That was there only to avoid a name conflict with the V1 column in the original data.
Thanks for your quick response. Yesterday we had a power outage due to a thunderstorm in my area. So I could not get back to you.
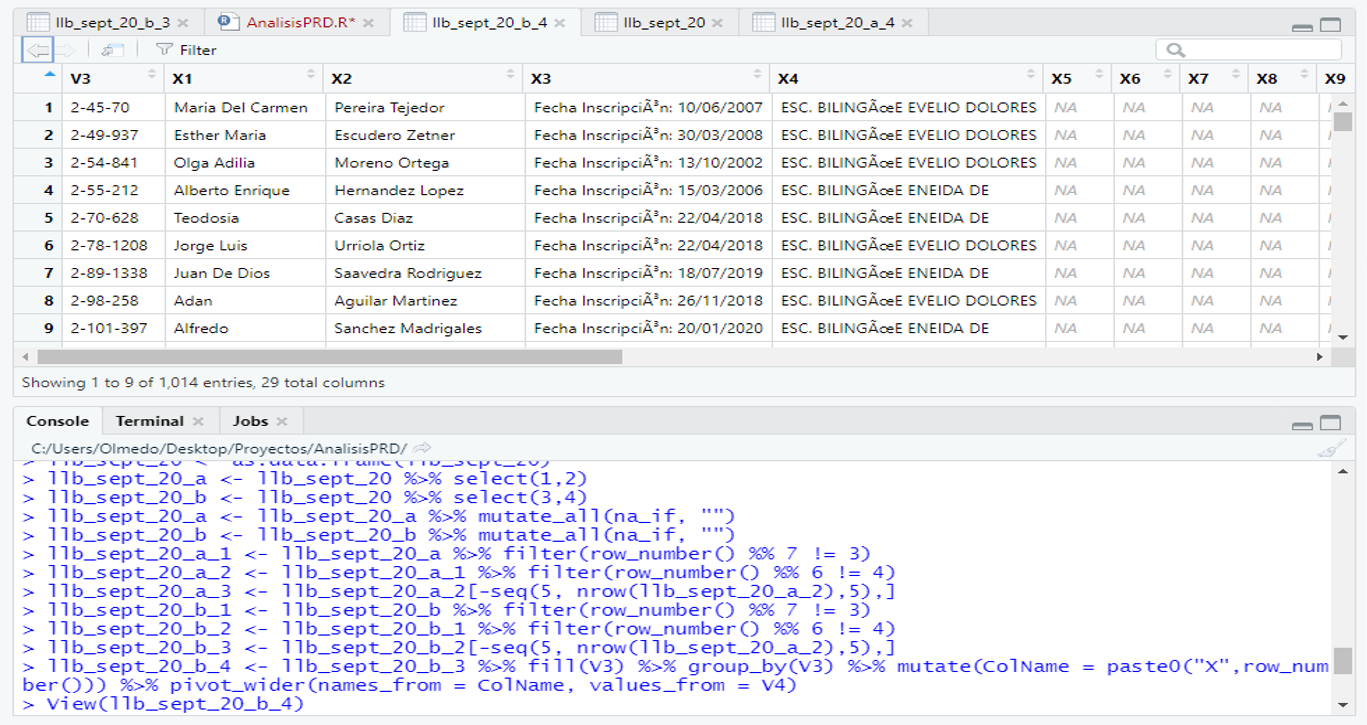
I ran the code and worked fine. The only issue is that it added other columns, from X5 to X28, filled with NA values. Let me show you the image. I appreciate your help.
Are those extra columns really NA in all rows? I expect somewhere there are some non-NA values. Find the V3 values of those rows and then inspect the original data for the reason so many rows are assigned to that V3. You may have missing values of V3 so that the fill() function keeps using the previous V3 value until a new one is encountered. You can find where you do not have NA with
Thanks for the help. You know, as you might have seen in the images, I split a pdf table in half to work it out better. Well, at the end of the last 3rd and 4th columns there were missing ID´s values. That´s why the NA columns from X5 to X28. But I did not spent time with it so I selected the columns I needed to work with. I solved it that way.
But now I face another issue. I have a similar pdf file that looks like the previous one and when I ran the function extract_tables() and do.call() an error comes up. I attach images of this issue. If you could help me with this. Thanks in advance.
This seems to be an entirely different problem having to do with Illegal Reflective Access by RJavaTools. Please start another topic with a descriptive title so others with knowledge about that will see it. I know nothing about RJavaTools.
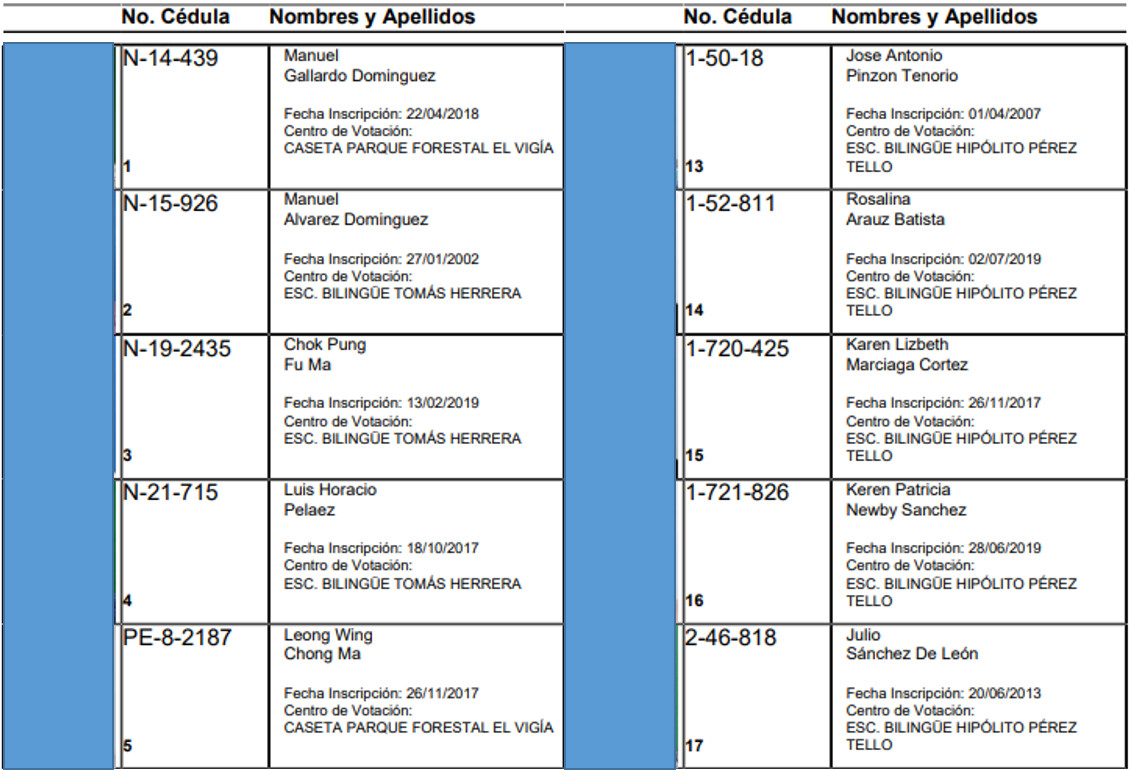
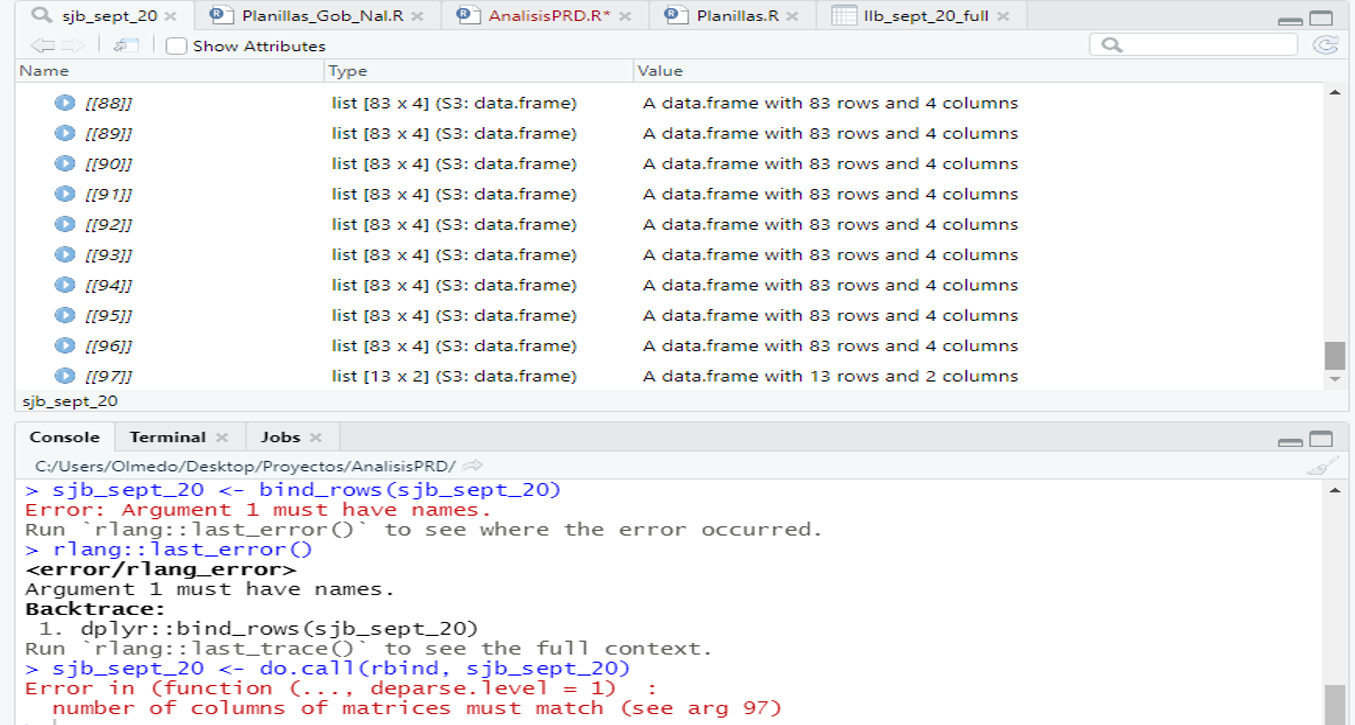
Sorry I write again. But in this case the error is about the number of columns do not match and send me to see argument 97. Actually this argument is at the end of the data frame and contains 13 rows and 2 columns and the 96 previous arguments have 83 rows and 4 columns. My question is now, how can I balance this difference in the 97 argument with this column difference?
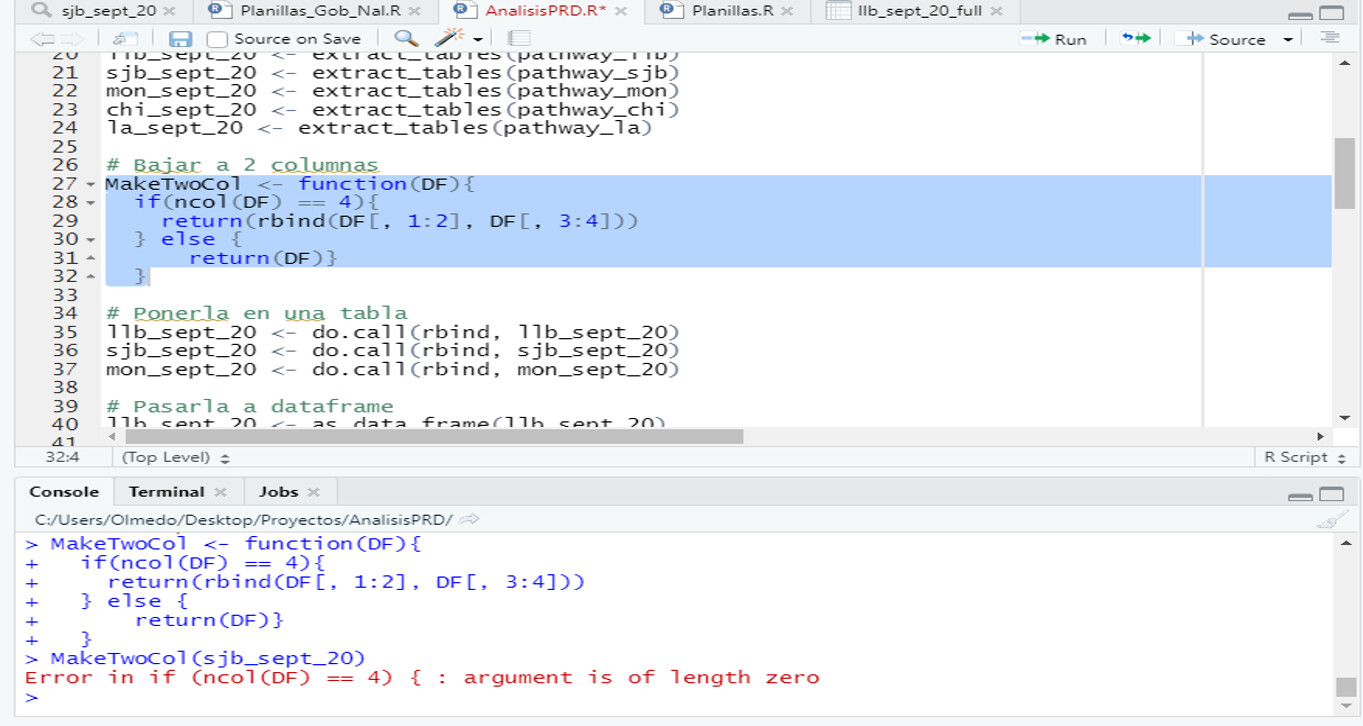
Judging from one of your earlier posts, each table in your document consists of two pairs of column. Each pair has No. Cedula and Nombres y Appellidos. I expect the last table only has one of those pairs because that was all that was needed to complete the data. It is a bad idea to have a data frame with columns with duplicate names, so the best solution is probably to rearrange all of the data frames that have 4 columns so that they have two columns. That is, take columns 3 & 4 and append them at the end of columns 1 & 2 so that the new data frame is 166 x 2 instead of 83 x 4. A function to do that would look like
I just wrote that without testing it, so it may well not be exactly right. After you run that on all of the 97 data frames, you will have a list where all of the data frames have two columns and you can rbind them.
I got it this time. I finally completed part of the task I am doing. If I need any other help with the other part I will write through here. Thanks again.