Hi!
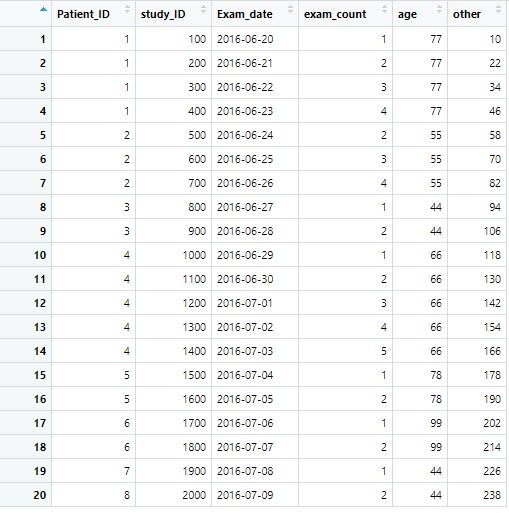
I have a very large dataset with patients that performed different number of examinations during a specific timeframe, so that each patient (Patient_ID) can have several "Study_ID", but I want to include only the one with the accompanying lowest "exam_count", or earliest date for this examination. Any good ideas on how I can achieve that? A fake version of some of the variables would look like this
Patient_ID study_ID Exam_date exam_count age other
1 1 100 2016-06-20 00:00:00 1 77 10
2 1 200 2016-06-21 00:00:00 2 77 22
3 1 300 2016-06-22 00:00:00 3 77 34
4 1 400 2016-06-23 00:00:00 4 77 46
5 2 500 2016-06-24 00:00:00 2 55 58
6 2 600 2016-06-25 00:00:00 3 55 70
So, I want to include only one study for each Patient_ID, and that should be the one with either the earliest "Exam_date" or the lowest "exam_count" (that would be same thing). Btw the lowest exam_count is not necessarily "1" due to prior exclusions made. I upload the fake data if needed.
Thank you in advance
Thomas