I try it again with a different example. In this case the I took the example of the prison population in Australia.
I removed most of the rows to reduce the size of the file and
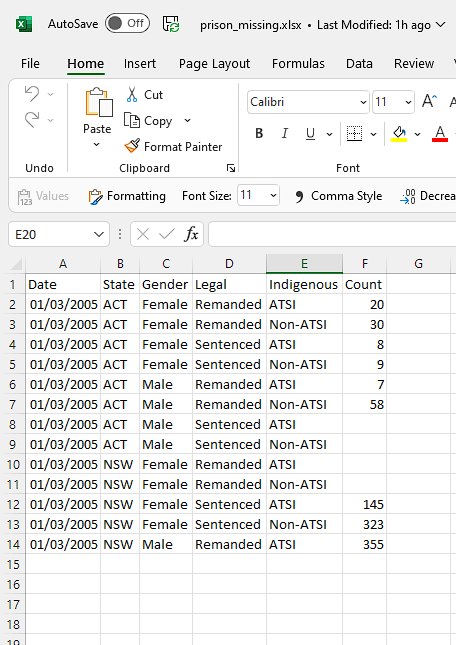
I deleted some values from the column Count In order to create some NA¨s.
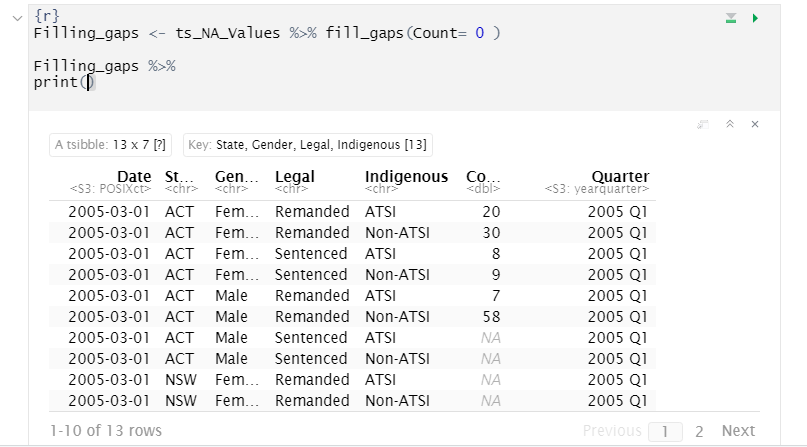
its not clear how your code relates to the screenshot of a view.
if your screenshot of a view was made by immediately viewing ts_NA_Values after running only the code provided then I think the answer is simply that you did not assign the result of fill_gaps to a named object; so you are viewing ts_NA_values as it was without fill_gaps having operated on it.
in R <- is used as an assignment operator, as can be seen when you first create ts_NA_Values from the read_xlsx function; the principle is the same
Sorry i would be more careful reading the functions nex time. thanks!
if we take my spreadesheet what would be an example of implicit missing values?
or if you can point me in the right direction i can investigate myself
your example is small; there is only a single date '2005-03-01' ; only one quarter 2005Q1.
supposing there were examples of 2005Q3 in there two; and your tsibble is quarterly then the absent records 2005Q2 would be implicit NA's and I would think fill_gaps would generate them.
I'm not super familiar; I rarely work with timeseries