I'm working on a ML project where some of the features are population demographics, reported as a % of the total population. Looking at some of the demographic distributions, it looks like there may be some non-linear relationships with the predicted variable - aka, things get wonky near 0% & 100% :
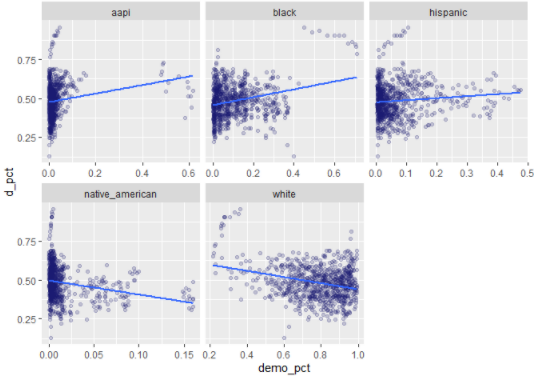
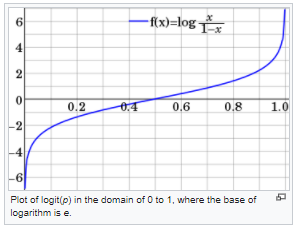
Are there any recommended first-steps for feature engineering w/data on a 0-1 scale? My first thought is to create new features by running the demographic data through the logit function to map the distribution from 0 - 1 to -inf and inf, but I'd happily welcome other ideas. I did a cursory google search & didn't come across any general info quickly.
Thanks ahead of time!